Försöksmetodik. Grunder
4. FÖRSÖKSDESIGN
4. 1 Undersökning som ett led i större projekt eller försöksverksamhet
Vi har hitintills behandlat grundläggande forskningsmetodik för en enskild undersökning. Men undersökningar är ofta också sammankopplade med varandra. Inom traditionell vetenskap är följande undersökningsförlopp vanligt:
- Det startar med idéer eller frågor om en empirisk företeelse.
- Man gör förförsök, som leder till preliminära hypoteser om företeelsen.
- De följs av flera hypotesstyrda experiment och andra typer av systematiska undersökningar, som resulterar i fakta och generaliserade principer.
- Sedan följer kommunikation av resultaten och tillämpningar av fakta och teoretiska principer i form av förklaringar och prediktioner av samma och liknande empiriska företeelser.
Med högre kunskapsmognad inom ett område följer undersökningarna vanligtvis på varandra i en sekvens, som bestäms av tidigare resultat eller av en speciell teori. Vetenskapligt baserad kunskap byggs alltså normalt upp systematiskt och i den takt som krävs för att resultaten (fakta) ska vara tillförlitliga och giltiga.
När det däremot gäller praktiska problem, som är omfattande och komplexa och kanske kräver att vissa lösningar eller mål måste nås inom en visst tidrymd, blir bilden delvis annorlunda. Ett exempel är uppgiften att utveckla ett nätverksbaserat försvar. Denna uppgift inrymmer båda framtagande av ny kunskap och design av nya alternativa medel. Av både praktiska och teoretiska skäl kan inte processen bedrivas fullt ut systematiskt och uttömmande. Man måste ofta göra vägval och hitta genvägar. Alberts och Hayes (2002) kallar den metodiska ansatsen för ”Experimentation campaign”, som bl.a. ska bidra till att konventionell ledning kan transformeras till nätverksbaserad.
Termen ’experimentation’ motsvarar närmast ’försök’ i vår terminologi. ”Experimentation campaign” är alltså en försöksverksamhet, som följer rekommendationerna i Code of Best Practice av Alberts och Hayes. Rekommendationerna eller koden är helt i överensstämmelse med vetenskaplig metodik. I Alberts och Hayes’ begreppsvärld finns tre typer av försök:
- Discovery experiments – snarast en form av förförsök eller pilotstudier
- Hypothesis testing experiments – hypotesstyrda försök
- Demonstration experiments – demonstrationer
Blandningen av sådana olika typer av försök är en av de egen-skaper, som skiljer ansatsen från en konventionell vetenskaplig försöksserie. En ”experimentation campaign” är en speciell mix av vetenskapliga undersökningar och utvecklingsarbete. Utvecklingsarbete börjar med analyser av användare, miljöer samt önskvärda funktioner och uppgifter, som systemet ska ha. Det följs sedan av upprepade cykler av designarbete och test (jfr ’Discovery experiments’).
4.2 Krav på försöksmetodik vid utvecklingsarbete
Målet för utvecklingsarbetet att transformera Försvarsmaktens ledningssystem kräver givetvis en betydande bredd i försöksverksamheten. Olika typer av försök måste inriktas och samordnas, vilket är speciellt besvärligt, eftersom NBF-målet inte är specifikt formulerat. Utvecklingsarbetet berör många kunskapsområden, och lösningarna ska fungera i varierande sammanhang för olika användare och miljöer.
En principiell svårighet i utvecklingsarbete är att man ofta inte är säker på att beslut och vägval är korrekta, och man inte kan förutse konsekvenser av felaktiga beslut. Häri ligger en skillnad mellan traditionell vetenskaplig kunskaps-uppbyggnad och praktisk försöksverksamhet för att nå vissa mål eller skapa fungerande lösningar. Vetenskapen har sin styrka genom självkorrigerande metodik för att nå säker kunskap. Utvecklingsarbete är i högre grad styrt av innovationer, försök att producera nya lösningar, oftast med krav på kostnadseffektivitet och kvalitet. Risken finns att felaktiga vägval på ett tidigt stadium kan vara svåra att upptäcka förrän i slutskedet, då systemet blir operativt. Tillämpat på utvecklingen av NBF, skulle det exempelvis kunna innebära att tekniska innovationer föregriper och styr design och test av taktik och stridsteknik. Om denna anpassning inte är optimal, visar det sig i värsta fall först på slagfältet.
Figur 4.2 ger exempel på hur ett felaktigt beslut eller alternativval i början av ett utvecklingsförlopp kan fortplanta sig genom processen. Det ställs speciella krav på försöksmetodiken i varje led för att upptäcka och korrigera skevheter. Att ett designalternativ kan vara olämpligt är svårt att identifiera, eftersom detta val ofta omärkbart begränsar det fortsatta testande. Exempelvis blir utfallsrummet i prövningen inskränkt till endast ett fåtal alternativ, som framkommit tidigare i utvecklingsprocessen. Svårigheten inbegriper också eventuella kontrollbetingelser i testet, då dessa väljs mot bakgrund av huvudalternativet, i syfte att kontrastera det. Risken är stor att själva testningen får karaktären av en självuppfyllande profetia, som inte kan korrigeras förrän sent i utvecklingsarbetet eller när det är operativt.
Figur 4.2. Risker för felbeslut och typer av försök för att upptäcka dem.
För att i tid upptäcka och bearbeta konsekvenser av utvecklingsarbete krävs följaktligen en kvalificerad försöksmetodik. Samspelet mellan att utveckla och testa lösningar i realistiska situationer ställer särskilda krav på försöksmetodisk kompetens. Alberts och Hayes är mycket tydliga på den punkten i förordet till sin Code of Best Practice: ”Därför behöver försöksverksamhet (experimentation) bli Försvarsdepartementets nya kärnkompetens och inta sin rätta plats vid sidan av våra utbildnings- och träningskapaciteter som redan är av världsklass.” (översatt citat från Preface, sid xi).
4.3 Design av ett enskilt försök
Grunderna för uppläggning av ett försök har presenterats i kap 1-2 av kompendiet samt av Graziano och Raulin (kap 2-3) och Alberts och Hayes (kap 5). Vi ska knyta an till grundbegreppen från en utgångspunkt i problemanalysen (jfr avsnitt 3.10 i kompendiet). Ett allmänt råd är att inleda problemanalysen med att strukturera problemet, gärna med hjälp av en systembeskrivning. Den låter sig enkelt översättas till en allmän beskrivning av undersökningsdesign.
Figur 4.3 kan illustrera ett försök, där undersökningsobjektet är någon form av system. Oberoende variabler X beskrivs som systeminput, och beroende variabler Y som output. Övriga variabler Z är störande eller ovidkommande (confounding variables), därför att de hindrar oss att dra en logiskt korrekt slutsats om relationen mellan oberoende och beroende variabler. Z-variablerna måste alltså kontrolleras, vilket kan ske i form av systematisk kontroll (eliminering, konstanthållning, utbalansering) eller genom randomiserad kontroll (genom en slumpprocess fördelas felen approximativt lika över betingelserna). Någon form av randomiserad kontroll är önskvärd i alla typer av försök, eftersom den är den enda kontrollmetod som inte förutsätter att man känner till de ovidkommande variablerna och hur de inverkar. Graden av randomiserad kontroll bestämmer ytterst möjligheterna att dra skarpa logiska slutsatser från ett försök.
De ovidkommande variablerna motsvarar omvärldsfaktorerna i systemanalysen. I den mån de inte är kontrollerade, så kan de ha systematiska respektive osystematiska (slumpmässiga) effekter på undersökningsobjektet (systemet). Försöksdesign handlar om att lägga upp försöket på ett sådant sätt att systematiska och osystematiska störeffekter reduceras.
Figur 4.3. Beskrivning i variabel- resp. systemtermer av ett försök.
4.3.1 Kravet på reliabla resultat från försök
Kontrollen av osystematiska (slumpmässiga) felkällor bestämmer om resultaten blir reliabla. Reliabiliteten bestäms i princip av hur många oberoende observationer som görs i försöket. Skälet till det är ganska uppenbart och hänger samman med definitionen av slumpfaktorn e. I varje enskild observation kan tillfälligheter spela in och snedvrida resultatet. Ju fler observationer som görs, desto mer sannolikt är det att sådana slumpeffekter tar ut varandra. Det kan uttrycks matematiskt som E(e)=0, då n→∞. Det utläses som att väntevärdet E för slumpfelet e är 0, då n, antalet observationer, blir oändligt. (Väntevärdet E kan tolkas som ett medelvärde M för ett oändligt antal observationer, n.). Den viktiga förutsättningen är att observationerna är oberoende. T.ex. ett 10-tal observationer är statistiskt inte mer värda än en enda, om observationerna är beroende av varandra, dvs. i praktiken är påverkade av en och samma systematiska felkälla. Det går att uppskatta i förväg hur många oberoende observationer som krävs för att få en godtagbar statistisk reliabilitet i resultatet. Uppskattningen grundas på en bedömning på variationen i observationerna (mer om detta i ett senare kapitel).
Den praktiska konsekvensen för försöksdesignen är att det behövs många oberoende observationer, om kontrollen över potentiella slumpmässiga felkällor är bristfällig. Kan man däremot visa att tillfälligheter inte har spelat in, räcker det med en enda observation.
4.3.2 Kravet på valida resultat från försök
Valida eller giltiga resultat förutsätter att man har kontroll över systematiska felkällor. Det allmänna begreppet ’validitet’ är sammansatt och innefattar flera olika perspektiv på resultat. Graziano och Raulin redogör ingående för de klassiska typerna av validitet samt de viktigaste typerna av störvariabler (kap 8, s.190ff) och kontrollåtgärder mot dem (kap 9). I Figur 4.3.2 illustreras tre validitetstyper som en introduktion till redogörelsen i Graziano och Raulin.
Resultat kan ofta beskrivas med hjälp av statistisk metodik. En grundläggande validitets- och reliabilitetsaspekt är då statistisk validitet (eller statistisk beslutsreliabilitet). Den gäller om resultatet (sambandet) beror på en systematisk effekt eller på slumpvariation. Med andra ord handlar det om att resultatet ska ha en godtagbar reliabilitet. Är detta fallet så talar man om att resultatet är ”statistiskt signifikant”, dvs. ej ett resultat av slumpen.
En statistiskt säkerställd relation säger inte mycket om hur meningsfullt resultatet är. Begreppsvaliditeten beror på hur väl man ”översatt” den hypotetiska begreppsrelationen till empiriska operationer och händelser. Överensstämmelsen förbättras naturligtvis av att begreppen är väldefinierade, och man har tillgång till en stor metodarsenal. Valet av både begrepp och empiriska operationer ska göras så att de blir klart avgränsade från andra alternativa hypoteser och begrepp.
Den j avser om man kan generalisera det hypotetiska sambandet till andra fall med t.ex. andra deltagare, tider, platser, situationer och uppgifter. Generaliseringsfrågan uppkommer formellt sett först efter att man fått en hypotes bekräftad empiriskt i ett försök. Men redan vid designen av det ursprungliga försöket bör man ta hänsyn till möjligheterna att generalisera kommande resultat.
Figur 4.3.2. Illustration av tre validitetsaspekter.
Den interna validiteten kräver att man kan bevisa empiriskt att relationen mellan oberoende och beroende variabler är kausal. Det innebär att effekten på en beroende variabel måste komma från den oberoende variabeln och inte från ovidkommande variabler. Observera att internvaliditeten gäller den empiriska relationen mellan operationellt definierade oberoende och beroende variabler – och inte den hypotetiska begreppsrelationen. Kontroll av ovidkommande faktorer spelar härvid en avgörande roll. Målet vid all försöksdesign är följaktligen att försöka komma så nära idealet som möjligt med att demonstrera en kausal relation.
4.3.3 Betydelsen av kontrollrestriktioner för försöksdesign
Generellt gäller det att ju fler välmotiverade kontrollrestriktioner man inför i ett försök, desto bättre blir den interna validiteten (se ”Levels of constraint”, Graziano & Raulin, s. 46-51). Denna princip kan emellertid stå i motsatsställning till andra validitetsaspekter som generalisering och begreppsvaliditet. Vi ska återkomma till detta senare. Figur 4.3.3 illustrerar schematiskt olika typer av undersökningar med varierande kontrollrestriktioner.
Figur 4.3.3. Schematisk illustration av undersökningar med olika kontrollrestriktioner.
Icke-systematisk observation av system i sina naturliga sammanhang kan inte användas för att testa hypotetiska samband. Restriktionerna är få, vilket leder till ett relativt godtycke i valet av vad som observeras och upptäcks. Distinktionen mellan oberoende (x) och beroende variabel (y) är i praktiken omöjlig att upprätthålla. Samma sak gäller distinktionen mellan undersökningsvariabler
(x, y) och övriga omvärldsfaktorer (z).
En systematisk fallstudie efterforskar bestämda x,y-variabler, vilket i sig innebär nyttiga restriktioner på vad som observeras. En vanlig enkel fallstudie saknar dock ofta explicita hypoteser om samband, vilket kraftigt begränsar dess värde vid både datainsamling och resultatanalys. Den interna validiteten blir självfallet låg i studier, som har få kontrollrestriktioner. Men det är också svårt att generalisera från slutsatser av naturalistiska försök och fallstudier, eftersom de är så präglade av de speciella undersökningsförhållandena. Även begrepps-validiteten är svårbestämbar; relationen mellan begreppen och de empiriska händelserna är diffus, beroende på att de observerade händelserna är inbäddade i en komplex naturlig kontext.
Både naturalistiska observationer och enkla fallstudier kan ha stort värde som förstudier till mer avancerade undersökningar. De kan ge nödvändig information om speciella individer, grupper, uppgifter, situationer och miljöer, som underlag för hypotesbildning och undersökningsplanering. De kan också användas för att testa om det är möjligt att generalisera tidigare undersökningsresultat till naturliga situationer. (Se vidare Graziano och Raulin, kap 6, s.120-138.)
I en korrelationsdesign är x- och y-variablerna i allmänhet utvalda och definierade före datainsamlingen. Ofta görs ingen åtskillnad mellan oberoende och beroende variabler. Styrkan och riktningen i de statistiska sambanden mellan variablerna bestäms och testas med eller utan explicita hypoteser. Kausala slutsatser är omöjliga att dra på grund av att man normalt inte kan bevisa att man har kontroll över ovidkommande variabler. Att fastställa en korrelation, ett statistiskt samband, är inte samma sak som att bevisa ett orsak-verkan-samband. Korrelationsdesignen kan vara av tvärsnittstyp, dvs. alla variabelmätningar görs vid ett enda tillfälle, eller av longitudinell typ, dvs. mätningarna fördelas över tid i syfte att mäta förändringar. Frågeformulär är den överlägset vanligaste data-insamlingsmetoden vid korrelationsstudier, särskilt av tvärsnittstyp. (Se vidare Graziano och Raulin, s.139-152, 158-161, 169-172.)
En differentiell design undersöker skillnader mellan grupper av individer eller andra enheter. Vanligtvis genomförs undersökningen som en korrelationsstudie, där exakt samma variabler används för respektive grupper. Den differentiella designen delar därför vissa svagheter med korrelationsdesignen. Den interna validiteten kan dock vara starkare än korrelationsdesignen, eftersom det finns en tydlig oberoende variabel i skillnaderna mellan ”naturliga” grupper. Kontrollen över ovidkommande faktorer är dock betydligt sämre än i experiment, eftersom fördelningen av individer (enheter) på grupper inte sker slumpmässigt utan följer den naturliga indelningen. Det är stor risk för att de ovidkommande variablerna skiljer sig mellan grupper och därför påverkar de beroende variablerna på ett okontrollerat sätt. (Se vidare Graziano och Raulin, s.152-157, 161-172.)
En experimentell design utmärks för det första av att en eller flera oberoende variabler manipuleras aktivt av försöksledaren. Det innebär att man inför en kontrollbetingelse (kontrollgrupp) till den experimentella betingelsen (gruppen):
Experimentell betingelse X
Kontrollbetingelse - (icke-X)
Alternativt kan olika experimentella betingelser tjänstgöra som kontroller till varandra:
Experimentell betingelse Xa
Experimentell betingelse Xb
För det andra fördelas antingen deltagarna i undersökningen (individer, grupper, enheter) slumpmässigt på experiment- och kontrollbetingelserna, eller omvänt, experiment- och kontrollbetingelserna slumpmässigt på deltagarna. Det är innebörden i begreppet randomiserad kontroll. Därigenom blir det möjligt att dra kausala slutsatser (kravet på intern validitet kan uppfyllas). Kontrollen av ovidkommande variabler kan ofta drivas långt, tack vare att försöksledaren kan bestämma över när, var och hur försöket ska genomföras.
4.3.4. Olika typer av experimentell och kvasiexperimentell design.
Experimentella designer kan ses som förebilder till att utforma ett försök. Skälet är naturligtvis att dessa designer av logiska skäl är effektivast i att kontrollera olika hot mot validiteten i resultaten. Det finns två grundformer av experimentell design. Figur 4.3.4 visar exempel på respektive designtyper.
Figur 4.3.4. Exempel på grundformer av experimentell design.
Den ena designtypen – oberoende grupper – förutsätter att deltagare fördelas slumpmässigt på två eller fler experiment- och kontrollbetingelser. Den randomiserade kontrollen ska säkerställa att grupperna blir likvärdiga (inom slumpens gränser). Genom att öka antalet deltagare i grupperna, n, så ökar sannolikheten för att grupperna blir likvärdiga (genomsnittligt). Kontrollgrupps-design innebär att en experimentgrupp med behandling (treatment) jämförs med en kontrollgrupp utan behandling. Ett annat exempel är när två eller flera grupper med olika behandling jämförs med varandra. Det finns ett flertal olika varianter av kontrollgrupps-designer med oberoende grupper. (Se vidare Graziano och Raulin, s.222-228, 233-238.)
Den andra designtypen – beroende eller korrelerade grupper – innebär att samma individ genomför alla betingelser (inompersonsdesign) eller att man bildar par (eller tretal osv.) av likvärdiga personer, som slumpas på den ena eller andra betingelsen (design med matchade grupper). (Se Graziano och Raulin, s. 246-247.)
I inomgruppsdesignen är varje deltagare kontrollperson till sig själv. Det kräver att ordningsföljden mellan betingelserna slumpas eller utbalanseras på annat sätt, eftersom det finns risk för att effekterna av olika betingelser annars sammanblandas. I designen med matchade grupper ingår andra, likvärdiga individer som kontrollpersoner i alla betingelser. Förutsättningen är givetvis att man kan genomföra matchningen på ett ändamålsenligt sätt. (Se vidare Graziano och Raulin, s. 248-259. )
Designer med beroende grupper fordrar normalt färre deltagare (n), under förutsättning att antingen den experimentella behandlingen tillåter att samma individ deltar i flera betingelser (inompersonsdesign) eller att de matchade deltagarna verkligen är likvärdiga (design med matchade personer). Inompersonsdesignen är särskilt känslig för s.k. progressiva effekter under försökets gång och att olika effekter av betingelserna sammanblandas i resultatet. Exempel på progressiva effekter är trötthet, inlärning osv. Uppfylls inte kontrollvillkoren så är generellt sett designen med oberoende grupper säkrare. De statistiska konsekvenserna av olika designer utreds i ett senare kapitel (Graziano och Raulin, 238-242.)
4.3.4. Kvasiexperimentell design
I fältförsök är det oftast inte möjligt att genomföra (äkta) experiment. Den viktigaste anledningen till det är att man inte kan använda sig av randomiserad kontroll. Graziano och Raulin (s. 207-216) redogör ingående för kontroll genom sampling (urval) och randomisering (slumpning) av deltagare på betingelser.
S.k. kvasiexperimentella designer är de ”näst bästa” att använda, när det gäller att pröva kausala hypoteser. Graziano och Raulin (s. 292) anger fem utmärkande egenskaper hos kvasiexperimentella designer:
- Kausala hypoteser formuleras (som i experiment)
- Minst två betingelser eller nivåer i den oberoende variabeln används (som i experiment), men försöksledaren kan inte alltid manipulera den oberoende variabeln aktivt.
- Deltagarna kan vanligtvis inte fördelas (slumpmässigt) på grupper (betingelser), utan man måste acceptera redan existerande grupper.
- Designer bör kompletteras med speciella procedurer för att kunna testa kausala hypoteser.
- Speciella kontroller måste till för att kontrollera hot mot validiteten.
Avvikelser i punkt 2 och 3 från experimentkraven är anledningen till att designerna kallas kvasiexperimentella. Punkt 4 och 5 innefattar olika medel för att kompensera dessa designbrister, så att det ändå blir möjligt att resonera om resultaten i kausala termer.
Vi kan illustrera designproblematiken med hjälp av vårt exempel med den allmänna hypotesen att lägesinformation påverkar lägesuppfattning. En specifik forskningshypotes är:
H1: Ökad mängd lägesinformation av typen Xa förbättrar lägesuppfattningen.
Vi inleder med att först granska en oacceptabel design, som inte uppfyller kraven på ett kvasiexperiment – men inte desto mindre tyvärr är vanlig i praktiska sammanhang! (Se Graziano och Raulin, s.216-219.)
Antag att en försöksledare försöker testa hypotesen H1 med följande design på en grupp deltagare, som inkluderar förtest yF och eftertest yE av lägesuppfattningen, där x’a innebär ett tillskott av information jämfört med den vanliga situationen.
"Experimentgrupp" yF x'a yE
Om eftertestet ger en bättre lägesuppfattning än förtestet, yE > yF, så är försöksledaren benägen att dra slutsatsen att det beror på tillskottet av information x’a, dvs. att hypotesen H1 bekräftas. Detta är emellertid felaktigt, eftersom de logiska villkoren för en kausal slutsats inte uppfyllts med denna design. Designen är oanvändbar om den inte byggs ut med kontroll av hot mot den inre validiteten. Det gäller att kontrollera effekten av ovidkommande faktorer z, annars kan ingen slutsats dras om effekten yE > yF, vilket framgår om vi inkluderar felkällorna z:
"Experimentgrupp" yF x'a & z yE
Exempel på ovidkommande variabler, som kan påverka resultatet, är historia, testning, regression mot medelvärdet, bortfall (attrition), sekvenseffekter (Graziano & Raulin, s. 190-197, 230f).
En experimentell design kan uppfylla det logiska kravet genom att inkludera en kontrollgrupp, som inte får informationstillskottet x’a.
Experimentgrupp yF x'a yE
Kontrollgrupp yF – yEk
Övriga kontroller innefattar bl.a. att experiment- och kontrollgrupp är likvärdiga, vilket uppnås genom randomiserad fördelning av tillräckligt många deltagare på grupperna (Graziano & Raulin, s.234f). Om detta villkor är uppfyllt, kan man t.o.m. utesluta förtestet. Det räcker med att jämföra skillnaden i yE för experiment- och kontrollgruppen (ibid s.233f).
Förutom kontrollgruppsdesign kan man ibland använda inompersonsdesign och design med matchade grupper. I detta hypotetiska fall är det fullt möjligt.
I vårt exempel är det inga svårigheter att manipulera den oberoende variabeln. Det går att testa hur lägesuppfattningen påverkas genom att använda varierande mängder av lägesinformation. I praktiken kan det emellertid ibland vara svårt eller t.o.m. inte önskvärt att fördela deltagare slumpmässigt på experiment- och kontrollgrupp
Antag att en försöksledare vill pröva en hypotes om två olika sätt att bearbeta lägesinformation av en viss typ, dvs jämföra två olika uppgifter a och b:
H2: Uppgiften a att bearbeta lägesinformation ger bättre lägesuppfattning jämfört med uppgiften b.
Försöksledaren vill pröva hypotesen ”skarpt” eller med andra ord på stabsmedlemmar i krigsförband. Frågan är om detta går att genomföra med en experimentell design? Svaret är ja om man väljer staben som deltagande enhet. Ett alternativ är att sampla ett stort antal staber, som sedan fördelas slumpmässigt på betingelserna a och b (kontrollgruppsdesign). Det kan dock vara praktiskt ogörligt. Om försöksledaren i stället väljer att använda enskilda stabsmedlemmar som deltagare men vill utnyttja det faktum att de arbetat i samma stab, så finns det olika alternativa sätt att designa ett jämförande test. Exempelvis:
- jämföra stabsmedlemmar från skilda staber, som redan har olika arbetssätt (a eller b),
- jämföra stabsmedlemmar från skilda staber som inte prövat vare sig a eller b (eller som har samma arbetssätt),
- försöka matcha individerna i skilda staber, så att grupperna (staberna) blir likvärdiga,
- låta stabsmedlemmarna i en eller flera staber pröva både uppgift a och b i testet.
Icke-ekvivalenta kontrollgruppsdesigner. De två första designerna är kvasiexperimentella och exempel på icke-ekvivalenta kontrollgruppsdesigner (Graziano & Raulin, s.292-296; jämför också det första fallet med vad som tidigare sagts om differentiell design.) De uppfyller alltså inte experimentkravet (3 ovan) på randomiserad fördelning av deltagare på betingelser. Detta är det vanligaste fallet vid fältstudier. Hot mot den interna validiteten beror på två förhållanden: (i) grupperna kan från början skilja sig i förmåga att generera en lägesuppfattning, och (ii) de kan skilja sig i andra avseenden (z; t.ex. motivation) som kan påverka prestationen. Olika kontrollåtgärder kan dock hjälpa till att kompensera för dessa brister. Exempelvis kan förtest göras för att mäta ev. skillnader, vilket kan användas för att värdera resultatet.
Design med matchning av individer från redan existerande grupper är mer komplicerat än det kan verka (Graziano & Raulin, s.254-259). Det är ofta svårt att finna effektiva matchningsvariabler, och urvalet av personer att matcha kan vara begränsat. Resultatet av matchningen kan mycket väl bli att grupperna (paren etc.) inte är ekvivalenta
Tidsseriedesign. Möjligheten att använda en experimentell inompersonsdesign avgörs av om testen med uppgifterna a och b kan betraktas som oberoende, dvs. inte påverka varandra (Graziano & Raulin, s.248-254). I detta fall prövar alla deltagare båda arbetssätten. Som tidigare nämnts är inompersonsdesignen känslig för ordningseffekter och interaktioner mellan olika betingelser. Ett kort experimentförlopp av denna typ blir sannolikt också starkt påverkat av deltagarnas tidigare erfarenhet. Det kräver att man garderar sig mot denna felkälla genom att använda en mer avancerad design.
En kvasiexperimentell design som är en utveckling av inompersonsdesignen är tidsseriedesignen (Graziano & Raulin, s.296-300). I den genomförs en serie förmätningar eller test för att etablera en ”baslinje”, därefter genomförs den experimentella betingelsen, och en serie eftertest vidtar för att jämföra resultaten mot baslinjen.
Experimentpersoner yF1, yF2, yF3, yF4, … xa, yE1, yE2, yE3, yE4,…
(Ev. kontrollpersoner yF1, yF2, yF3, yF4, … – yE1, yE2, yE3, yE4,…)
Upprepade mätningar, gärna över en längre tid (longitudinell design) bidrar till att säkerställa att resultaten är stabila. Inför man kontrollpersoner, så stärks designen ytterligare. Designen kan även användas för enskilda fall (single-subject designs; Graziano & Raulin, s.261).
Multipla indikatorer eller beroende variabler. Att använda flera olika indikatorer eller beroende variabler (multiple baselines) är ett utmärkt sätt att kontrollera effekten av såväl oberoende variabel som ovidkommande variabler (Graziano & Raulin, s.306). En väl genomförd problemanalys ligger till grund för att förutsäga att vissa indikatorer eller beroende variabler ska påverkas av den oberoende variabeln, medan andra indikatorer kan vara speciellt känsliga för ovidkommande variabler. Ytterligare en annan grupp av indikatorer kan ha uppgiften att signalera att vissa faktorer har varit konstanta under försöket. De olika indikatorerna ska alltså tillsammans bilda ett mönster, med vars hjälp resultaten kan analyseras mer ingående. Att använda multipla indikatorer är en nödvändighet i mer avancerade fallstudiedesigner.
4.4 Andra avancerade fältdesigner
Följande designtyper är egentligen hybrider av olika enklare designer och metoder. De används vid mer komplicerade fältstudier och utvecklingsarbeten.
4.4.1. Avancerad fallstudiedesign
Enkla former av fallstudier används som en form av förförsök. Mer avancerade former beskrivs av bl.a. Yin (2003). Hans karakteristik av sådana fallstudier är att de har samma fokus som experiment på forskningsfrågorna om hur och varför något sker. Men de kräver inte kontroll av beteendehändelserna. Komplicerade brotts- och haveriutredningar har en likartad ansats, skillnaden kan vara att den vetenskapliga fallstudien vanligtvis också har syftet att producera generell kunskap och inte bara förklara den specifika händelsen. Yin’s (2003 s.13f) definition av en fallstudie är:
1. A case study is an empirical inquiry that
- investigates a contemporary phenomenon within its real-life context, especially when
- the boundaries between phenemenon and context are not clearly evident.
2. The case study inquiry
- copes with the technically distinctive situation in which there will be many more variables of interest than data points, and as one result
- relies on multiples sources of evidence, with data needing to converge in a triangulating fashion, and as another result
- benefits from the prior development of theoretical propositions to guide data collection and analysis.
Med andra ord ska den avancerade fallstudien styras av teoretiskt motiverade och kontrasterande hypoteser. Hypotesprövningen kräver ett bevisunderlag i form av multipla indikatorer eller datakällor, och ett stort antal variabler är relevanta för att beskriva och förklara fenomenet i fråga. Man skulle kunna säga att vad som saknas av experimentell kontroll av händelser i fallstudien måste kompenseras genom att teoristyra insamlingen och analysen av data.
Fallstudietaktiken liknar en brottsutredning, bl.a. för att man ska söka oberoende evidens som bildar en sammanhängande beviskedja och att man ska konfrontera berörda ”vittnen” med resultatet – i syfte att stärka begreppsvaliditeten. Yin’s rekommendationer att stärka den interna validiteten är mer överraskande, eftersom den interna validiteten egentligen endast avser den empiriska relationen och inte modellplanet. Några av taktikerna är uppenbarligen att modellmässigt skapa en kausal referensram för data, som eljest inte uppfyller de empiriska kontrollkraven på kausalitet. Däremot är ”rivaliserande hypoteser” inget annat än det generella kravet på att varje hypotes ska motsvaras av en kontrasterande hypotes om ett alternativt utfall.
Yin’s allmänna rekommendationer om hur man kontrollerar hot mot validitet och reliabilitet i fallstudien kan vara värda att referera:
Man hävdar ofta att resultaten av en enskild fallstudie inte kan generaliseras till andra fall, beroende på alla specifika omständigheter som varit förhanden. Yin påpekar att det inte är frågan om en statistisk generalisering av resultatet till en statistisk population av fall. I stället ger resultatet av fallstudien möjlighet till en analytisk generalisering, dvs. de teoretiska slutsatserna kan tillämpas på nya fall. I fråga om multipla fallstudier, så är de jämförbara med upprepade experiment (replikationslogisk generalisering). Rekommendationerna för att testa reliabiliteten syftar till att oberoende bedömare ska kunna upprepa analysen av data, så att felkällor kan upptäckas och korrigeras. En utförlig och noggrann dokumentation av data är förutsättningen för detta.
4.4.2. Programutvärdering
Liksom fallstudien genomförs en programutvärdering i en naturalistisk kontext. Den utmärkande skillnaden är, som framgår av beteckningen, att man ska utvärdera om ett program nått sina mål. Det finns alltså normer eller kriterier för hur resultatet ska utvärderas. Figur 4.4.2 visar ett exempel på en program-utvärderingsmodell (efter Mohr, 1992).
Figur 4.4.2. Exempel på modell för programutvärdering.
Programmet är i detta fall uppbyggt som en integrerad sekvens av mål-medel-strukturer. Varje aktivitet syftar till att nå ett delmål eller bidra till slutmålet. Delmålsstrukturen är placerad på s.k. resultatlinjer – i detta fall två parallella linjer som utgör förutsättningar för att nå delmål 5. Programmet kan utvärderas formativt – processutvärdering av delmålsuppfyllelse – eller summativt – utvärdering av slutresultat visavi målen. Om inte delmålsstrukturen redan finns uttalad i programmet, så är det möjligt att teoretiskt konstruera en sådan struktur i samband med att man planerar en processutvärdering. Valet av beroende variabler sammanhänger intimt med programmålen.
Utvärderingen av effekten av programaktiviteter kan utnyttja olika basala försöksdesigner. Olika designer kan användas för skilda delmål beroende på typ av aktiviteter och resultatvariabler (Graziano & Raulin, s. 309-314).
4.4.3. Aktionsforskning
Aktionsforskningsansatsen har presenterats tidigare i avsnitt 2.5. Den innehåller drag av både avancerade fallstudier och programutvärdering, samtidigt som den inrymmer en kvasiexperimentell strategi, tack vare det inslaget av aktiva interventioner eller aktioner. Aktionsforskning innefattar upprepade cykler av diagnos – intervention – uppföljning och feedback – nya interventioner – uppföljning och feedback osv., tills problemet är löst eller förändringen av systemet är genomförd (Figur 4.4.3) Valet av specifika försöksdesigner och metoder görs utifrån syften och situation och kan dessutom växla betydligt under aktionsforskningsförloppet.
Figur 4.4.3. Exempel på cykler vid aktionsforskning.
Aktionsforskningen sker uteslutande i naturalistisk kontext och är därför förenad med etiska problem och förpliktelser. Det framgår av Lewins sammanfattande principer för aktionsforskning (efter Schein, 1980).
1. Ingenting är så praktiskt som en bra teori.
2. Om du vill studera en organisation (system, grupp), så försök att förändra den.
3. Forskningsmodeller som inbegriper kontrollgrupper och kontrollerad experimentell manipulation är varken lämpliga eller önskvärda för att hantera mänskliga system.
4. En vetenskap om grupper och organisationer kan byggas med ”kvasiexperimentella” modeller och en aktionsforskningsfilosofi genom att designa organisatoriska interventioner (ej experimentella behandlingar) och studera deras effekter.
5. Varje mätning (förutsatt att den inte är fullständigt icke-störande) för att utvärdera effekten av en tidigare intervention blir själv automatiskt nästa intervention.
6. Etiken för forskningsinterventioner kan inte särskiljas från etiken för interventioner genom konsultation och terapi.
I och med beskrivningen av aktionsforskningsansatsen har vi kommit tillbaka till kapitlets utgångspunkt om mixen mellan utvecklings- eller förändringsarbete och traditionell vetenskaplig undersökningsmetodik. Slutsatsen är att fundamentala försöksdesigner är basen även för avancerat vetenskapligt och utvecklings-inriktat arbete i naturlig kontext.
_______________
5. UNDERSÖKNINGSMETODER – KVALITATIVA OCH KVANTITATIVA INDIKATIONER OCH MÅTT
Som tidigare kapitel visat, är begreppet ’validitet’ sammansatt av olika aspekter eller perspektiv, som kompletterar varandra. Försöksdesign handlar i första hand – men inte uteslutande – om att skapa förutsättningar för att resultaten ska ha intern validitet. Syftet är att kunna dra kausala slutsatser på grundval av resultaten. ”Undersökningsmetoder” handlar närmast om att skapa god begreppsvaliditet – att observera ”rätt saker” – dvs. empiriska företeelser som är relevanta visavi de begrepp som är i fokus.
5. 1 Begreppsvaliditet och undersökningsmetodik
Vi tar begreppsvaliditeten, överensstämmelsen mellan begrepp och empiriska observationer, som utgångspunkt för att introducera olika typer av undersökningsmetoder (jfr Figur 4.3.2). Med undersökningsmetoder menar vi mera exakt metoder för att göra empiriska observationer och registrera dem som data. Begreppet ’observation’ har här en allmän betydelse: ”att inhämta information” (Figur 5.1.1).
Figur 5.1. Relationen mellan begrepp och empirisk observation.
Termen ’variabel’ kan avse både teoretiska variabler (begrepp) och empiriska (observerbara) variabler. I stället för ”empirisk variabel” används ofta beteckningen ’indikator’, särskilt då det finns flera alternativa och indirekta sätt att observera motsvarande teoretiska variabel (begrepp). Exempelvis olika indikatorer på begreppet ”lägesuppfattning” kan omfatta att en försöksperson själv konstruerar en lägesbild (reproduktion), får välja rätt lägesbild bland alternativ (igenkänning), svarar på faktafrågor om läget (återgivning) eller vär-derar olika konsekvenser av läget (bedömning).
Hur bedömer man om begreppsvaliditeten är godtagbar? Det finns naturligtvis inget facit eller enkelt svar på den frågan, eftersom uppgiften är att skaffa ny kunskap inom ett empiriskt område. Det finns två typer av anledningar till att man kan få låg överensstämmelse mellan ett begrepp och motsvarande indikator (data). En anledning är att metoden innehåller felkällor, och en annan är att undersökningsmetoden inte är relevant för begreppet ifråga. Begreppsvaliditeten kan bara säkras efterhand genom upprepade insatser av såväl teoretisk som empirisk art. Det finns dock ett antal vägledande principer för att stärka begreppsvaliditeten.
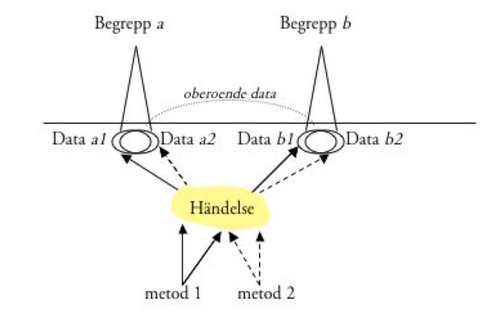
En sådan princip är ”konvergerande operationer” (triangulering). Den innebär att man bör använda så många oberoende empiriska operationer (metoder) som möjligt för att fastställa en empirisk observation eller motsvarighet till begreppet ifråga. Figur 5.1.2 visar ett exempel med två metoder, som indikerar en stor mängd överlappande information i data. Datamängderna 1 och 2 har alltså ett starkt samband; det tyder på att de kan representera samma begrepp a. Konvergerande operationer eller indikatorer för begreppet ”mängd lägesinformation” kan t.ex. omfatta antalet meddelanden per tidsenhet, hur många informationsenheter ett genomsnittligt meddelande innehåller, subjektiv bedömning av meddelandenas antal eller komplexitet osv.
Att de empiriska observationerna görs oberoende innebär definitionsmässigt att de inte inkluderar exakt samma felkällor. Den praktiska grundregeln är att välja metoder som är så ”olika” som möjligt. För att begreppsvaliditeten ska vara godtagbar krävs det att de olika observationerna indikerar samma sak, dvs. har ett högt inbördes samband. Men om metoderna liknar eller är beroende av varandra, dvs. har gemensamma felkällor, så kan man få ett samband mellan data som kallas ”gemensam metodvarians”. Exempelvis subjektiva bedömningar är ofta utsatta för en s.k. ”haloeffekt” – bedömningen av en framträdande egenskap påverkar bedömningen av andra egenskaper. Ett annat exempel är förekomsten av allmänna negativa eller positiva svarstendenser, som skapar en inflation i negativa, eller alternativt positiva, svar på frågor i en enkät. Denna felvarians får inte förväxlas med den ”sanna innehållsvariansen”, som indikerar begreppsvaliditet, dvs. att metoderna täcker samma begreppsliga innehåll. Tillvägagångssättet för att säkra begreppsvaliditeten mot den gemensamma metodvariansen illustreras nedan i anslutning till ett praktikfall.
Figur 5.1.2. Konvergerande operationer testar begreppsvaliditeten.
Resonemanget om konvergerande operationer gäller också omvänt. Kan man inte fastställa ett samband mellan de olika indikatorerna på samma förmodade händelse eller begreppsinnehåll, har man heller ingen grund för att bekräfta begreppet i fråga. Det saknar då ”konvergerande validitet”.
En annan princip för att etablera begreppsvaliditet är att demonstrera att begreppet i fokus inte har samma betydelse som andra besläktade begrepp. Exempelvis om man vill använda ett begrepp som ”psykisk stress” (a) för att beskriva en företeelse, så bör man kunna visa att det inte kan ersättas med andra tillgängliga begrepp med en delvis annan innebörd, som t.ex. ”trötthet” (b). Denna aspekt på begreppsvaliditet kan kallas ”diskriminerande validitet”, dvs. man måste kunna göra en meningsfull åtskillnad mellan olika begrepp.
Figur 5.1.3 illustrerar att a-begreppets indikatorer måste skilja sig från b-begreppets, för att a-begreppet ska motivera sin oberoende ställning i förhållande till b-begreppet. I exemplet används samma metoder 1 och 2 för att testa begreppen a och b. Metoderna 1 och 2 antas vara olika, men de visar ändå stark konvergerande validitet för varje begrepp för sig. Men de respektive datamängderna a och b är sinsemellan oberoende, vilket styrker den diskriminerande validiteten. Begreppen a och b kan alltså antas beskriva eller förklara olika egenskaper hos händelsen ifråga. Detta är ett exempel på en fullständig prövning av begreppsvaliditeten. Tillvägagångssättet beskrivs ytterligare i ett praktikfall nedan.
Figur 5.1.3. Diskriminerande validitet: indikatorer särskiljer begrepp.
5.2 Utvidgat test av begreppsvaliditet: multivariabel – multimetodmatris
Vi ska granska ett utvidgat tillvägagångssätt att testa begreppsvaliditeten i ett praktikfall om lägesuppfattning. Antag att man har upptäckt att läges-uppfattningen i vissa ledningssituationer är oacceptabelt dålig. Försöksledaren har två rivaliserande hypoteser Ha och Hb om att stor mängd lägesinformation respektive olämplig bearbetningsteknik har medfört att lägesuppfattningen är bristfällig. Objektiva indikatorer på den oberoende variabeln ’informationsmängd’ kan t.ex. vara antalet meddelanden per tidsenhet, meddelandenas komplexitet osv. Objektiva indikatorer på den oberoende variabeln ’bearbetningsteknik’ kan t.ex. vara tillgång till tekniska hjälpmedel samt färdighet i bearbetningsteknik. Ett försök genomförs, där man observerar och registrerar objektiva data och dessutom låter deltagarna göra subjektiva bedömningar av informationsmängd och bearbetningssvårigheter.
Resultaten kan sammanställas och tolkas med hjälp av en ”multivariabel-multimetodmatris” enligt exemplet i Tabell 5.1.2.
Begreppsvaliditeten bedöms med hjälp av sambandsanalys. Man inser lätt att en grundläggande förutsättning för att få valida resultat är att de är reliabla, dvs. inte slumpmässiga. Första uppgiften är därför att kolla reliabiliteten i varje indikator (metod) för respektive variabel (se cellerna i matrisens huvuddiagonal). God reliabilitet innebär i detta sammanhang att resultat med samma indikator och variabel har ett mycket högt samband.
Tabell 5.1.2. Tolkning av samband mellan variabler och metoder (indikatorer) för exemplet med orsaker till bristande lägesuppfattning.
Testning av reliabiliteten kan ske med olika metoder. De vanligaste är att upprepa observationerna på samma sätt (test-retestmetod), att göra parallella men oberoende observationer (parallelltestmetod), eller att beräkna överensstämmelsen mellan ett stort antal ekvivalenta indikatorer (homogenitetstest). Testmetoderna mäter som synes delvis olika aspekter på reliabilitet. I praktikfallet kan man inte upprepa exakt samma lägesexempel med test-restmetoden, eftersom deltagarna minns det första testet. Man måste använda olika lägesexempel av samma typ eller välja en annan testmetod. En möjlighet är t.ex. parallelltestmetod med olika, oberoende bedömare. Ett annat alternativ är att konstruera ett mycket stort antal olika lägesexempel eller indikatorer och göra ett homogenitetstest.
Därefter bedömer man begreppsvaliditeten, som förutsätter att det finns ett påtagligt samband mellan olika men konvergerande (objektiva och subjektiva) indikatorer för samma variabel (begrepp). Naturligtvis kan det finnas en god begreppsvaliditet, även om man bara har en enda välvald indikator på variabeln ifråga. Men då har man endast begränsad kunskap om hur generellt och användbart begreppet är. I praktikfallet skulle konvergerande begreppsvaliditet för t.ex. variabeln ’informationsmängd’ innebära att flera olika objektiva och subjektiva indikatorer överensstämmer (har höga samband).
Sambandet för konvergerande begreppsvaliditet bör dessutom vara högre än övriga resterande samband i matrisen. Annars är variabeln antingen för allmänt definierad (saknar diskriminerande validitet) eller en skenprodukt av ett metodsamband (gemensam metodvarians). I det förra fallet kan inte de olika indikatorerna skilja mellan variablerna ’informationsmängd’ och ’bearbetnings-teknik’. Det senare fallet innebär exempelvis att subjektiva bedömningar av lägesinformation och bearbetningsteknik kan överensstämma enbart på grund av att samma subjektiva svars metod har använts.
5.3 Typer av variabler och indikatorer
Graziano och Raulin (kap 3) beskriver en grov klassifikation av variabler i användning (form) och egenskaper (innehåll).
Formklassifikation. Hit kan man räkna indelningen i oberoende, beroende och inskjutna variabler, men också distinktionen mellan teoretiska (begrepp) och empiriska variabler. I Figur 4.3 används också termen ”ovidkommande variabler” (störfaktorer) för att beteckna variabler, som bör kontrolleras vid sidan av oberoende och beroende variabler.
Innehållsklassifikation. Det finns ett otal sätt att klassificera variabler med avseende på innehåll – från allmänna till specifika egenskaper. Vilka man väljer att använda beror på syftet med försöket och vad som är brukligt inom ämnesområdet ifråga.
En klassisk indelning i experimentalpsykologin är mellan Stimulus- (S), Organism- (O) och Responsvariabler (R). Ibland ersätts beteckningen organismvariabel med personvariabel. Gäller det reglersystem, så tillkommer också feedbackvariabler. En mängd alternativa termer brukar användas för att specificera försöket ytterligare, t.ex. situations- kontra uppgiftsvariabler, instruktionsvariabler etc. eller individernas reaktioner, t.ex. prestationsvariabler.
En besläktad beskrivning är i termer av människa och miljö. Vissa variabler är entydigt kopplade till endera människan eller miljön, medan andra är uttryck för deras växelverkan. Människan påverkar eller gör avtryck i miljön. Miljön i sin tur sätter sin prägel på människan. Människa-maskin-system inbegriper många exempel på interaktiva variabler.
En betydande mängd variabler är definierade med hjälp av fysiska, tekniska, ekonomiska, administrativa m.fl. begrepp. Det gäller t.ex. beskrivningar av verksamheter och deras konsekvenser. Exempelvis verkan av stridshandlingar kan definieras i termer av bl.a. fysiska, ekonomiska, taktiska och humanitära konsekvenser.
En särskilt viktig indelning av variabler hänger samman med analysnivåer. En verksamhet kan exempelvis analyseras på organisations-, grupp- och individnivå, varvid variabeldefinitionerna skiljer sig innehållsmässigt. Beskrivningen av en organisatorisk händelse skiljer sig alltså från en social eller individpsykologisk beskrivning, när det gäller ingående begrepp, även då alla tre analysnivåerna gäller en och samma fysiska aktivitet eller händelse.
En fundamental indelning av beroende variabler inom psykologin är den mellan beteenden och upplevelser. I det dominerande vetenskapsteoretiska ”realism-perspektivet” kan inte (personliga) upplevelser observeras direkt på ett objektivt sätt, utan bara genom beteendet (t.ex. via självrapportering). Beteende-observationer är alltså det empiriska fundamentet för att generera data inom beteendevetenskapen – tillsammans med andra objektiva beskrivnings-system av aktiviteter och fysiska och kulturella artefakter (t.ex. fysiska spår och dokument).
Ibland är biologiska eller psykofysiologiska variabler relevanta för att beskriva eller förklara sambandet mellan miljöfaktorer och psykologiska variabler, t.ex. i form processvariabler eller inskjutna variabler.
Vi talar om subjektiva och objektiva data för att beteckna ursprunget eller fokus för observationerna. För subjektiva data är det upplevelser (tankar, känslor etc.), och för objektiva data är det fysiska och kulturella händelser och objekt. Kravet i realism-perspektivet (och i dess föregångare, positivismen) är att den vetenskapliga observationen i sig ska vara objektiv.
Silverman (2001) beskriver några alternativa kontrasterande vetenskapssyner vid sidan av det vetenskapsteoretiska huvudstråket. De är besläktade med ”förståelselära” (hermeneutik) och har fått en spridd användning inom bl.a. psykoterapi och feministisk forskning m.m. eller ingår i journalistik vid beskrivning av människans villkor. ”Emotionalismen” karakteriserar Silverman som en ”romantisk föreställning” om att man kan få autentiska data om människors upplevelser genom öppna, ostrukturerade intervjuer. ”Konstruktionism” utgår oftast från att en objektiv vetenskap om människans upplevelser inte är möjlig utan måste ersättas med att forskare-deltagare gemensamt konstruerar kunskap, t.ex. genom utforskande samtal (Silverman, s.87).
Det traditionella vetenskapsidealet handlar i mångt och mycket om att kontrollera felkällor, som har sin grund i begränsningarna i människans förmåga att uppfatta, tolka och använda information på ett rationellt sätt. Det förutsätts att det existerar en fysisk verklighet – oberoende av den mänskliga föreställningen om den (Graziano & Raulin, s.28f).
Ett särskilt kontrollproblem i vetenskapligt arbete är att man måste räkna med att undersökningsobjektet/deltagaren (människan, gruppen, organisationen) är reaktiv, dvs. reagerar medvetet eller omedvetet på att bli observerad – ibland kallat ”försökskanineffekten”. Ett särskilt komplicerat sammanhang är när deltagaren med rätt eller orätt tror sig kunna förstå syftet och undersöknings-metodiken och kan påverka resultatet medvetet. Detta är regel snarare än undantag i beteendevetenskapliga studier
5.3 Allmänt om undersökningsmetoder
Vi har definierat begreppet 'undersökningsmetod' som en empirisk (fysikalistiskt observerbar och beskrivbar) operation för att generera data, som också är fysiskalistiskt registrerbara. Samma typ av metod kan ofta användas för att generera olika typer av data. Exempelvis subjektiva bedömningar kan användas för att göra både kvantitativa bedömningar med hjälp av en skala och kvalitativa beskrivningar med naturligt språk. I teknisk mening kan en metod bestå av olika delar: exempelvis en uppgift eller instruktion till deltagaren och/eller observatören, särskilt konstruerade stimuli och/eller naturligt förekommande informa-tion, samt en svarsteknik som kan vara bunden och begränsad eller tillåta fria och öppna svar. Vidare kan t.ex. observationen göras öppet eller dolt och icke-störande. Observationen kan ske i realtid eller avse en historisk händelse, som dokumenterats, registrerats eller lämnat andra fysiska spår.
Konventionella metodtyper som systematiska och deltagande observationer, intervjuer, frågeformulär, bedömningstekniker, fysiska registreringar och mätningar, fysiska och kulturella artefakter, analyser av arkiv och dokument osv. kan användas på ett flertal olika sätt. De bör under alla omständigheter granskas noga med avseende på felkällor och vilka data avsikten är att de ska generera. Metodlitteraturen i beteendevetenskap är synnerligen omfattande och bör absolut konsulteras, innan man använder en speciell metod.
I princip kan alltså alla former av metoder och datainsamling nyttjas, så länge de är relevanta för syftet och begreppsapparaten i försöket.
Gränsen mellan en metod och den vidare databehandlingen är inte alltid klar. I princip kan registrerade data ofta bearbetas och tolkas med hjälp av ett flertal olika datamodeller. Vi fokuserar därför fortsättningsvis främst på datatyper, eftersom de är intimt kopplade till begreppen i hypoteser och frågeställningar. Metodvalet bör i själva avgöras med hänsyn till att data kan kopplas på ett meningsfullt sätt till de relevanta begreppen.
5.4 Kvalitativa data
De flesta metoder kan generera kvalitativa data. Undantagen är egentligen bara de metoder som direkt genererar fysiska mått som tid, längd, laddning m.m., och som samtidigt representerar naturlagar (se 5.5).
Det finns ett praktiskt taget obegränsat antal olika kvalitativa sätt att karakterisera objekt och händelser. Att bringa en innehållsmässig ordning i allt detta är en uppgift för alla vetenskaper tillsammans. Det är lättare att ta en utgångspunkt i vad som formellt kännetecknar en kvalitativ beskrivning. Grundbegreppet, som vi redan stött på upprepade gånger, är klassifikation. En strikt logisk klassifikation innebär ju att olika element ur en grundmängd kan klassificeras i ett antal ömsesidigt uteslutande klasser. Dessutom måste alla element i grund-mängden kunna klassificeras på detta sätt, dvs. klassifikationen måste vara uttömmande.
Metoderna bör alltså utformas och användas så att dessa logiska krav uppfylls. Ofta är det en alldeles nödvändig förutsättning för att viss databehandling ska kunna göras, t.ex. statistisk analys och sannolikhetsberäkningar. Det underlättar också modellkonstruktion och logiska härledningar. Det kan finnas teoretiska skäl till att de formella kraven på klassifikation inte bör upprätthållas; då talar man om s.k. ”oskarp logik”. Men i allmänhet är den formella klassifikationen det fundamentala instrumentet för att organisera data.
Empiriskt är det emellertid många gånger svårt att i praktiken klassificera data. Det beror ofta på en kombination av att klassifikationssystemet är olämpligt och att de empiriska händelserna komplexa och instabila. Undersökningsobjekten förändras kanske efterhand, så att de kategoribegrepp som användes inledningsvis i försöket inte är relevanta i slutet, vilket man inte lyckats förutse vid metodkonstruktionen. En lägesbeskrivning i början av ett komplicerat skeende kan skilja sig radikalt från beskrivningen i ett senare läge som inte förutsetts. Att utrusta deltagarna med fördefinierade beskrivningskategorier, som är tillämpliga i alla sammanhang, har ofta den nackdelen att begreppen blir för allmänt hållna och inte tjänar sitt syfte att reducera informationen utan att förlora i noggrannhet.
I sådana sammanhang använder man med förkärlek naturligt språk och obundna svarsmetoder. Det naturliga språkets flexibilitet och nyansrikedom ger visserligen stor frihet i databeskrivningen. Nackdelen är att det används och tolkas på mycket olika sätt. Det är alltså svårt att åstadkomma hög interbedömarreliabilitet och att tolka beskrivningar entydigt, när deltagarna har obundna svarsmetoder. I sådana fall blir det försöksledarens uppgift att klassificera svaren. Man flyttar alltså tolkningsproblematiken ett steg framåt i databehandlingen – från deltagaren till analytikern. Det är långt ifrån säkert att detta ökar validiteten i resultaten.
Under alla omständigheter behöver observerade och registrerade data klassificeras, även om proceduren kan variera. Det finns ett otal möjligheter att skapa sammansatta klassifikationer. Exempelvis om en enkel binär klassifikation {0,1} av händelser kan tillämpas för 10 olika egenskaper eller attribut, så ger det 210= 1024 olika sätt att klassificera element ur grundmängden. En indelning i tre grundkategorier i samma fall, t.ex. {Ja, Nej, Vet ej}, ger 310= 59049 klasser osv. Det går alltså i princip att åstadkomma en noggrann logisk beskrivning med ett fåtal grundklasser och ett måttligt antal beskrivningsattribut, under förutsättning att grundklasserna är ömsesidigt uteslutande och beskrivningsattributen gäller väsent-iga aspekter på undersökningsobjekten.
Exemplen illustrerar hur klassifikationssystem kan kombineras. Det logiska utfallsrummet är lika med produkten av alla klassningar. Utfallsrummet för två kombinerade klassifikationer R och K kan representeras med en matris, R×K. I vänstra exemplet i Figur 5.4 är utfallsrummet 2×3=6 klasser.
En hierarkisk klassificering sker vanligen i termer av över- och underordnade klasser. I exemplet till höger i Figur 5.4 är K-klasserna betingade på R, bara 3 kombinationer förekommer {K1⎜R1, K2⎜R1, K3⎜R2}, (utläses: K1 betingat på R1 osv).
Figur 5.4. Exempel på dubbel (t.v.) och hierarkisk (t.h.) klassificering.
En hypotesprövning, som gäller kvalitativa data, förutsätter alltså en utfallsrymd, där en eller flera klasser är förenliga med hypotesen, medan övriga klasser är oförenliga med den. I det vänstra fallet utgör utfallsrymden exempelvis en kombination av två sätt att förmedla information och tre typer av information. En hypotes kan vara att en typ av informationsöverföring R1 bara lämpar sig för två typer av information K1 och K2, samt att motsvarande gäller för R2 och K3. Hypotesen uttrycks följaktligen som en relation mellan R och K. Den kan formellt skrivas som H={〈R1,K1〉,〈R1,K2〉,〈R2,K3〉}, dvs. en mängd av tre par av ordnade klasser. Den hierarkiska klassningen till höger i Figur 5.4. beskriver samma relation eller hypotes grafiskt.
Förutom en formell beskrivning av kvalitativa data kan man avgränsa ett antal olika generella typer av kvalitativa data. De kan exempelvis innefatta naturligt språk, formella språk, grafik, bilder, dynamiska representationer (t.ex. video) av aktiviteter och kropps-språk, föremål, spår i miljön och andra fysiska effekter. För många av dessa beskrivningsmöjligheter finns det redan etablerade metoder och registreringstekniker inom respektive fackdiscipliner och teknologier.
Beteendevetenskapen nyttjar givetvis alla upptänkliga metoder och registreringstekniker från andra vetenskaper, i syfte att beskriva individuella, sociala och organisatoriska företeelser. De centrala beteendevetenskapliga metoderna för att samla in och tolka kvalitativa data gäller emellertid tal, text och interaktioner. Silverman (2001) ger en auktoritativ beskrivning av metoder inom kvalitativ forskning och diskuterar bl.a. den fullständigt meningslösa kontrovers, som finns mellan insiktslösa förespråkare för endera kvalitativ eller kvantitativ metodik. Självklart bör metodvalet styras av syftet med ett försök. Normalt krävs både kvalitativa och kvantitativa data i fältundersökningar.
Silverman (s.11ff) behandlar fyra huvudkategorier av kvalitativa metoder, nämligen observationer, text- och dokumentanalyser, intervjuer samt analyser av ljud- och videoregistreringar av naturligt förekommande interaktioner. Här kommer jag bara att återge hans sammanfattande punkter om respektive metodansats.
Observationer. Silverman (kap 3) konstaterar att det finns fyra kritiska aspekter på observationsstudier:
- Studiens fokus
- Etiska frågor
- Metodologiska val
- Teoretiska val
Enligt en ”naturalistisk” forskningsinriktning är fokus på att försöka observera göranden och låtanden utan förutfattade meningar – en strategi grundad på någons sorts sunt förnuft och direkt iakttagande och tolkning. Inriktningen är medvetet icke-teoretisk. Metodiskt försöker man observera de ”naturliga” sammanhangen. En kontrasterande ”etnometodologisk” ansats riktar kritiska invändningar mot samtliga dessa punkter, och påpekar bl.a. att observationer och tolkningar alltid är metod- och teoribundna, och därför bör erkännas och nyttjas konstruktivt som instrument i forskningen.
Systematiska observationer är den traditionellt vanligaste formen; den har förberedda observationskategorier. Deltagande observation förekommer också som en speciell metodvariant, då observatören medverkar aktivt som deltagare i de observerade aktiviteterna. Det innebär givetvis särskilda metodiska problem vad gäller reaktivitet m.m.
Intervjuer. Silverman (kap 4) framhåller att intervjuer erbjuder en speciellt rik källa till data om hur människor redovisar både med- och motgångar. Det faller teoretiskt inom området attributionsteori – hur människor subjektivt förklarar händelser och deras orsaker och konsekvenser. Man får emellertid akta sig för att utan vidare förväxla dessa utsagor med sanningen. Här förekommer ofta missbruk bland forskare, som består i att de antingen tar självrapporterna som äkta uttryck för upplevelser eller förkastar dem helt som subjektiva förvrängningar av verkligheten.
Silverman redovisar de tre olika modeller som nämnts tidigare för att hantera intervjuer och data: positivism (naturvetenskapligt perspektiv), emotionalism (empatisk förståelse) och konstruktivism (socialt konstruerade intervjusanningar).
Intervjuer är vanligen den mest ”provocerande” metod som en försöksledare kan använda. Det är en påtaglig interventionistisk teknik med många felkällor. Intervjutekniker finns det en mycket stor metodlitteratur kring, som bör konsulteras i samband med användning av metoden.
Textanalyser. I samhäller spelar verbaliseringar och produktionen av texter en viktig roll. Dessa data kan analyseras i efterhand; själva observationen och analysen av dem påverkar dem inte. Silverman (kap 5) skiljer mellan fyra typer av textanalys:
- Innehållsanalys. Den förutsätter en kategorisering av textinnehållet, och sedan en frekvensräkning av hur ofta kategorierna används. En kvalitativ klassifikation ligger alltså till grund för en kvantifiering.
- Analys av ”narrativa strukturer”. Det är språkligt semantiska analysen av ”berättelser” i någon form.
- Etnografi. Beskrivningar sammanställs om hur sociala händel-ser är strukturerade.
- Etnometodologi. Fokus är på hur människor använder olika sätt och tekniker för att förstå hur de själva och tillvaron är organiserad.
Textanalyserna syftar inte till att värdera eller kritisera innehållet i texterna. Syftet är att analysera hur texter fungerar som medel för att åstadkomma effekter.
Analys av naturligt förekommande tal och bild (Silverman, kap 6-7). Ljud- eller videoinspelningar förutsätts för att kunna göra tillförlitliga och noggranna analyser. Det finns två huvudtyper av analyser av naturligt tal: konversationsanalys och diskursanalys.
Konversationsanalysen är inriktad på detaljbeskrivning av regler för interaktioner, t.ex. i dialoger på hur deltagarna tar ordet och replikerar enligt vissa mönster eller regler. Diskursanalysen har större tonvikt på sociala och innehållsliga teman, hur retorik och argument används i den sociala kontexten.
Silverman (kap 7) hävdar att syftet med att studera ”visuella bilder” är att undersöka hur de fungerar socialt och psykologiskt. Flera forskningsgrenar har specialiserat sig på olika aspekter på detta: semiotik behandlar hur ”tecken” fungerar som meningsbärare; etnometodologi studerar hur människor utvecklar en ”förnuft-baserad geografi” för att lokalisera sig själva i tid och rum; konversationsanalytiker använder videoregistrering för att undersöka hur människor använder och reagerar på visuella element i miljön.
5.5. Kvantitativa data
Kvantitativa data har det gemensamt att de representerar mått på egenskaper i verkligheten, dvs. de kan uttryckas med hjälp av numeriska tal. Mätning innebär alltså att kvantitativa metoder genererar mått på egenskaper hos objekt eller händelser. Man skiljer på fundamental mätning och definitionsmässig mätning. Fundamental mätning används dagligen vid fysiska mätningar av t.ex. längd, vikt, buller m.m. Definitionsmässig mätning innebär användning av relativt godtyckliga mätskalor, t.ex. kunskapsprov, mer eller mindre etablerade genom praxis. Fysiken bygger som vetenskap ytterst på fundamental mätning av ett litet antal grundegenskaper i naturen som t.ex. längd, tid, massa, laddning. Nyttan av fundamental mätning beror på att den är förenlig med eller t.o.m. uttrycker naturlagarna.
I beteendevetenskapen är fundamental mätning sällsynt i samband med mätning av mer komplexa egenskaper. Enklare former av fundamental kan förekomma, men majoriteten av skalorna inom beteendevetenskapen är exempel på rent definitionsmässiga mått.
Vad är då fundamental mätning? Figur 5.5 illustrerar principerna med hjälp av schemat över begrepps- och empiriplan. Det som tillkommer jämfört med vanlig begreppsvalidering är två formella modeller. En är en numerisk modell för att utnyttja talsystemet till att beskriva egenskaper. Den andra är en lämpligt vald kvalitativ modell för att ”översätta” tal till kvalitativa empiriska operationer och vice versa. Det kallas ’avbildning’ i matematisk terminologi.
Figur 5.5. Principer för fundamental mätning av ’längd’.
Förfarandet exemplifieras i nedre delen av Figur 5.5. En kvalitativ operation för att avgöra om två längder x och y är fysiskt ekvivalenta med avseende på längd är att lägga dem sida vid sida. Operationen motsvarar den numeriska operationen (=) att två förekommande tal x och y är lika. Samma typ av fysisk operation används för att avgöra ordning (storlek), som motsvarar den matematiska operatorn >. Att kombinera två ekvivalenta objektlängder kan motsvara den numeriska operationen addition (+) respektive förlängning (mångfaldigande) genom multiplikation. De kvalitativa operationerna bygger på antagna naturlagar – att objektens egenskaper inte förändras under mätoperationerna. Därför kan mätningen betecknas som fundamental. Denna konstans medför också att man konstruera tekniska mätinstrument, som praktiskt förenklar mätoperationerna.
Mätningen kan göras på olika skalnivåer (Graziano & Raulin, s 77-79). Skalnivån avgörs av vilka numeriska operationer som har en meningsfull tolkning i termer av de empiriska operationerna. För den högsta skalnivån, kvotskalan, har samtliga matematiska operationer, = >, + och × (samt deras komplement ≠, <, - och /) meningsfulla motsvarigheter i empiriska operationer, och skalan har en absolut nollpunkt. Längdmätningen i Figur 5.5. är ett exempel på mätning på kvotskalenivå. Ett specialfall av en kvotskala är en s.k. absolut skala, där måttet utgör frekvensen eller det absoluta antalet element.
Intervallskalor har empiriska tolkningar som motsvarar addition och subtraktion, förutom ordningsrelationer. I en ordinalskala är bara rangordningsoperationerna översättbara till de numeriska ordningsrelationerna > och <.
Goda exempel på fundamental mätning på kvot- och intervallskalenivå är sällsynta i beteendevetenskapen. Däremot finns det exempel på definitionsmässig mätning på intervallskalenivå. De förutsätter att ett antal speciella antaganden är sanna, men detta kan inte prövas oberoende. Anledningen till att man ändå använder dessa skalor är att de kan bidra till bättre statistisk prediktion, t.ex. från testprestation till arbetsprestationer. Att minska osäkerheten något i förutsägelser om ett beteende är dock inte samma sak som att förklara samma beteende.
Att det krävs en viss försiktighet, när det gäller att tolka resultat av definitionsmässig mätning, framgår av följande exempel. Antag t.ex. att ett kunskapsprov konstrueras för att mäta resultat av en utbildning, informations-givning eller dylikt. Provet består av t.ex. 10 frågor eller uppgifter. En deltagare A får 7 rätt, en annan B får två rätt. Vilken typ av mätning har genomförts? Kan det röra sig om fundamental mätning av kunskaperna på ordinalskalenivå, eftersom deltagarna kan rangordnas – 7 rätt är otvetydigt mer än 2 rätt? Är inte deltagare A med flest rätt också den som har mest kunskap i enlighet med det kunskapsbegrepp som mäts? En sådan slutsats kan emellertid inte dras direkt, utan att man gör en rad antaganden om hur mätoperationerna har gått till!
Slutsatsen förutsätter bl.a. att man antar att uppgifterna är ekvivalenta beträffande kunskapskrav – om B har löst två uppgifter med högre kunskapskrav skulle det annars kunna uppväga A:s sju enklare uppgifter. Man måste också förutsätta att deltagarna löser uppgifterna i ungefär samma ordning om provet är tidsbegränsat – annars kan ju en tidig lösning av en svårare uppgift leda till tidsbrist för övriga uppgifter. Man måste vidare anta att andra variabler inte spelat in och påverkat prestationen, som t.ex. nervositet, dagsform, formuleringsmissar m.m. Mätningen har alltså karaktären av att vara definitionsmässig och inte fundamental. Dessutom är ordinalskalnivån inte självklar utan ett särskilt reliabilitetstest och användning av en noggrann mätprocedur.
Sensmoralen är alltså den att kvantitativa indikatorer måste begreppsvalideras noga för att de uppgivna måtten ska vara meningsfulla. Det förutsätter dels en precis beskrivning av mätproceduren och dels en redovisning av vilka teoretiska mätantaganden eller mätmodeller som försöksledaren använder.
Ett annat begreppsanalytiskt problem uppkommer. om man använder fysiska mått på psykologiska och sociala företeelser. Exempelvis tidmätningar (reaktionstid, beslutstid, tid att utföra en handling m.m.) är vanliga. Fysisk tid mäts fundamentalt på en kvotskala. Om man använder tidsmått som indikator (beslutstid) på ’beslutsförmåga’, mäter man då beslutsförmågan på kvotskalenivå? Svaret är i princip nej, eftersom man måste kunna visa med meningsfulla mätoperationer att en person som fattar beslut på hälften så kort tid som en annan, har dubbelt så stor ’beslutsförmåga’. Detta är f.n. inte möjligt, inte minst beroende på att begreppet ’beslutsförmåga’ inte är tillräckligt exakt definierat inom kognitionspsykologin. Det rör sig alltså om definitionsmässig mätning, i bästa fall fundamental mätning på ordinalnivå, om en precis mätmodell kan formuleras. I rent fysisk (icke-psykologisk) mening är emellertid de uppmätta tiderna på kvotskalenivå, och de kan utnyttjas t.ex. för att beräkna vilken tid som åtgår i stabsarbete etc.
Skalnivåerna vid mätning har viss betydelse för möjligheterna att tolka resultatet av statistiska test. I allmänhet är det tekniskt ”tillåtet” att göra vilka statistiska beräkningar som helst på ett siffermaterial. Men möjligheterna att dra meningsfulla slutsatser är beroende av skalnivån på kvantitativa data (se Graziano & Raulin, s.80). Till det problemet återkommer vi i ett senare kapitel.
5.6 Analysnivåer och analysstrategier
Indikatorer kan analyseras – ibland parallellt – på olika nivåer. Ett viktigt exempel, som tidigare nämnts, är analysnivåerna i en organisation: individ-, grupp- och organisationsnivå. På varje nivå skiljer sig såväl begreppen som indikatorerna, trots att samtliga analyser kan gälla samma fysiska aktiviteter eller händelser i organisationen. En viktig uppgift är då att försöka relatera de olika begreppen och datamängderna till varandra för att få en helhets-bild. Undersökningar av komplexa fenomen innefattar nästan alltid analyskrav av den här typen. Samtidigt är detta ett försummat område, beroende på att akademisk forskning ofta är ämnesmässigt koncentrerad till den ena eller andra ämnesnivån.
Tre analytiska strategier är: (1) att använda teoretiska principer, (2) att utnyttja kontrasterande och rivaliserande hypoteser, (3) att utveckla en fallbeskrivning eller deskriptivt ramverk för data. Den tredje strategin är den metodiskt svagaste men kan vara nödvändig i ett inledande undersökningsskede.
Datastrukturer av komplexa händelser kan bearbetas utifrån skilda perspektiv och med hjälp av olika analytiska tekniker. En teknik är att jämföra indiciemönster mellan olika betingelser, eller i relation till teoretiskt väntade resultat eller för att testa rivaliserande hypoteser. En annan teknik är att utveckla kausala scheman som förklaringsmönster till datastrukturerna. Olika former av tidsserieanalys kan användas för att t.ex. analysera om olika aktiviteter och effekter är tidsmässigt relaterade till varandra – sekventiellt och parallellt. Formella, logiska och matematiska modeller kan användas för att representera och bearbeta komplexa data, som t.ex. vid mätning. Korsvaliderande jämförelser kan göras mellan olika undersökningar och fall för att identifiera och bekräfta generella, återkommande strukturer i data.
6. KOPPLINGEN FÖRSÖKSDESIGN – DATAANALYS
I undersökningsplaneringen ingår det att klara ut hur data ska sammanställas och analyseras. Det påpekades i kap 3 (se Figur 3.12) att problemanalysen egentligen inte är avslutad förrän genomförandet av försöket eller datainsamlingen startar. Först när man har försäkrat sig om att databehandlingen bör kunna ge svar på frågeställningarna, är undersökningsplaneringen färdig. Att vänta till efter datainsamlingen med att försöka hitta någon lämplig analysmetod är ett alltför vanligt nybörjarfel, som oftast leder till låg kvalitet på undersökningsresultatet.
Att kontrollera och förbereda sin datasammanställning är en relativt enkel sak, när det gäller försöksdesigner av experiment- eller korrelationstyp, särskilt för kvantitativa data. Experimentell design och statistisk analysmetodik är intimt sammankopplade, och det finns ett otal handböcker i ämnet. Det förekommer också enkla scheman för val av statistiskt test och dataprogram (se Graziano och Raulin, kap 14 och Appendix E). Inför genomförandet av försöket är det synnerligen lämpligt att gå igenom kap 14 (Final preparations before data collection).
Datasammanställningarna varierar med försöksdesignen, men det finns några enkla grundprinciper som vi ska exemplifiera. De flesta datatyper kan sammanställas i kodad form i matriser. Undantaget är egentligen bara speciella typer av kvalitativa data.
6.1 Korrelationsdata
Den enklaste formen av korrelationsstudie representerar data för två kvantitativa variabler X och Y i två kolumner, där raderna betecknar individernas värden (för totalt n individer). Se Tabell 6.1a. Sambandet mellan variablerna uttrycks vanligen med någon form av korrelationskoefficient, rXY. Se Graziano och Raulin, s.108-111 beträffande användning av olika korrelationsmått vid statistisk beskrivning. Vanligtvis är antalet variabler i en korrelationsmatris betydligt större. Beträffande användning av korrelationsdesign i allmänhet, se Graziano och Raulin, kap 7).
Resultatet av en korrelationsstudie med k variabler brukar redovisas som i Tabell 6.1b, vilket ger k(k-1)/2 samband uttryckta som korrelationskoefficienter.
Tabell 6.1a. Två Tabell 6.1b. Korrelationsmatris
kvantitativa variabler. för k variabler.
Samband kan också bestämmas om en av variablerna i exemplet Tabell 6.1a är kvalitativ, t.ex. bestående av två kvalitativt skilda betingelser (X kodad som endera 0 eller 1; Tabell 6.1c). Om båda variablerna är kvalitativa, kan man bestämma beroendet mellan dem bara om det finns en frekvensfunktion f kopplad till klasserna Tabell 6.1d ger ett exempel på kombinationen av en variabel X med två klasser {1,0} och en variabel Y med tre klasser {A,B,C}. Det innebär att man måste ha gjort upprepade oberoende observationer av betingelsernas förekomst f.
Tabell 6.1c. Kvalitativ X Tabell 6.1d. Två kvalitativa variabler
och kvantitativ Y variabel. och frekvenser f av kombinationer.
6.2 Datasammanställning för experimentella designer
Data för experimentella designer kan alltid representeras i matriser. Grundformerna av experimentella designer har presenterats tidigare i avsnitt 4.3.4. Tabell 6.2a visar en datasammanställning av en design med en oberoende variabel X, som inkluderar två betingelser 1 och 2 och har oberoende grupper av försökspersoner på respektive betingelse. Y är den beroende variabeln. Den normala jämförelsen mellan betingelser är i form av medelvärdesskillnader (M1-M2).
Tabell 6.2b visar motsvarande datasammanställning för inompersondesign (eller matchade grupper).
Tabell 6.2a. Data vid design Tabell 6.2b. Data vid inompersondesign
med två oberoende grupper. eller två matchade grupper.
Graziano och Raulin introducerar deskriptiv och statistisk analys (kap 5 s.93-108, 112-117), som gäller centralmått (bl.a. medelvärden) och spridningsmått (bl.a. standardavvikelse). Se också s. 222-226 som behandlar kopplingen mellan experimentell design och statisk inferens.
Data från en design med två kombinerade oberoende variabler V och W med vardera två betingelser (faktoriell design, skrivs 2×2) exemplifieras i Tabell 6.2c. Ett exempel på en hierarkisk design, där det finns ett beroende mellan variablerna X och V, illustreras i Tabell 6.2d. Den senare designen tillåter bara begränsade slutsatser. Y är beroende variabel i båda fallen.
Tabell 6.2c. Faktoriell design Tabell 6.2d. Hierarkisk design
med två oberoende variabler. med två beroende experimentvariabler.
6.3 Multipla beroende variabler
Multipla beroende variabler i designerna ovan innebär bara att matriserna måste flerfaldigas. Alternativt kan man tala om flerdimensionella matriser. Den tvådimensionella matrisen i Tabell 6.2c blir tredimensionell eller måste dubbleras, när ytterligare en beroende variabel tillkommer osv.
Komplexa variabler är särskilt vanliga när försöksdesignen inkluderar kvalitativa variabler, som utgör klassifikationer. Tabell 6.3 är ett exempel på en trippelklassifikation av tre kvalitativa variabler A, B och C, som bygger på respektive 2, 2 och 5 klasser, där varje klassifikation är uttömmande och givit ömsesidigt uteslutande klasser. Det är följaktligen en 2×2×5 design, som tillåter upp till 20 olika ömsesidigt uteslutande svarsmönster. Indikatorn y represen-terar alltså effekten av tre olika faktorer. Tack vare att klassifikationen är uttömmande och har ömsesidigt uteslutande klasser, är det möjligt att genomföra statistiska frekvensanalyser, som i Tabell 6.1d.
Tabell 6.3. Kombination av tre kvalitativa faktorer och motsvarande indikator.
Om man tar bort de logiska restriktionerna på klassifikationen, dvs. att klasserna ska ömsesidigt uteslutande och uttömmande, blir den konventionella statistiska frekvensanalysen inte möjlig utan att man definierar om utfallsrummet. Exempelvis kan både A1 och A2 förekomma eller ingendera osv. Bara för A-klassifikationen finns det i princip 4 utfall {(∅,∅),(∅,A2),(A1,∅),(A1,A2)}. Denna typ av klassifikation för trippelklassifikationen A×B×C genererar totalt 220 svarsmönster (en informationskapacitet på 20 bits). Ett relativt enkelt klassifikationsschema har alltså kapaciteten att beskriva ett utomordentligt stort antal olika kvalitativa datamönster.
En hypotes, som testas med detta utfallsrum A×B×C, kan t.ex. innebära att en viss definierad delmängd av utfall yijk bekräftar hypotesen, medan övriga svarsmönster innebär att den ska förkastas.
6.4 Kvalitativa data i naturligt eller formella språk
Alternativet till att göra dataklassifikationer är att utnyttja andra representations-former, särskilt mer eller mindre begränsade delar av det naturliga språket eller formella logiska system. Det innebär att data inte sammanställs i matrisform, utan att man använder det regelsystem som gäller för respektive beskrivningssystem.
Fördelen med dessa beskrivningssystem är att man kan variera detaljerings-graden, i princip obegränsat. Nackdelen är att datareduktionen uteblir eller, om en sådan ändå genomförs, att reduktionen då kan bli otillförlitlig och skev. Ett exempel är om man försöker sammanfatta vad en person uttryckt i en öppen intervju i ett komplicerat ärende. Med s.k. strukturerade svarsinstrument kan man dock begränsa svarsalternativen och i princip övergå till en svarsklassifikation.
Ett alternativ är att använda logiska system för att analysera komplexa data, som registrerats med hjälp av t.ex. naturligt språk. Observationen ”Adam, som är chef, fattade ett felaktigt beslut” kan med mängdlära formaliseras och reduceras till: C∩¬K∩B och Adam∈C, där C=mängden chefer, K=mängden korrekta aktiviteter och B=mängden fattade beslut; ”∩” betecknar logiskt ”och” (snitt), ¬” betyder ”icke” och ”∈” är liktydigt med ”tillhör” (dvs. ”elementet Adam tillhör mängden chefer”). I och med en sådan formalisering kan man göra logiska bearbetningar av kodade data med hjälp av bl.a. datorprogram.
6.5 Slutsatser om kopplingen försöksdesign – dataanalys
Den idealiska uppläggningen av ett försök är alltså att problemanalysen leder till preciserade frågor eller hypoteser, som ligger till grund för att skapa en adekvat försöksuppläggning. Med adekvat menas att försöket kommer att ge tillförlitliga och giltiga slutsatser om frågorna och hypoteserna. Formen för datainsamling och dataanalys blir då en logisk följd av försöksuppläggningen. I allmänhet gäller det också att ju mer strukturerad försöksdesignen är, desto kraftfullare och mer systematisk kan databehandlingen bli.
Om försöket i stället handlar om att bearbeta och dra slutsatser om data som insamlats tidigare, är uppgiften väsentligt svårare. Man har inte haft aktiv kontroll över dataproduktionen och saknar kanske också viktig information om hur den gått till. Statistisk och kvalitativ bearbetning kan möjligen utföras, men mer ingående analyser och slutsatser är sällan görliga. Databehandling i efterhand kan inte reparera logiska brister i försöksplanering och genomförande. Valet av dataanalys bör vara en integrerad del i försöksplaneringen (jfr Figur 2.2).
_________________

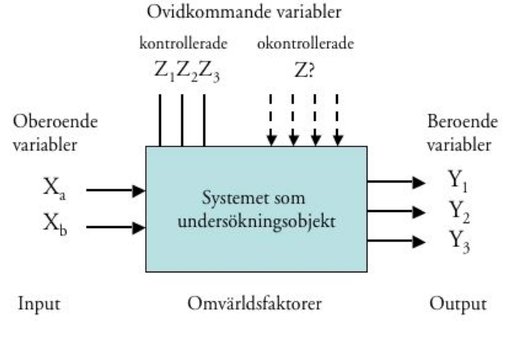
















Första upplagan av denna kompendieversion producerades för distanskursen Försöksmetodik för utvecklingsansvariga inom Försvarsmakten, A, 10 poäng, vid Umeå universitet, Enheten för arbets- och organisationspsykologi, utbildningsåret 2004/05. Kompendiet är en bearbetning av originalet från tidigt 1980-tal för kurser på A-nivå i Arbets- och organisationspsykologi vid Umeå universitet. Kompendiet får inte mångfaldigas utan författarens godkännande.
Forskargruppen för kommunikationspsykologi och ArbOrg Utveckling AB.
Bo Strangert, 2004, 2005, 2006
1. INLEDNING
2. GRUNDBEGREPP I VETENSKAPLIG METODIK
3. PROBLEMANALYS – FORMELLA ASPEKTER
4. FÖRSÖKSDESIGN
5. UNDERSÖKNINGSMETODER – KVALITATIVA OCH KVANTITATIVA INDIKATORER OCH MÅTT
6. KOPPLINGEN FÖRSÖKSDESIGN – DATAANALYS
_________________________________________________________________________
Förord
Kompendiet är ett styrinstrument för kursen i försöksmetodik 2006. Det ska underlätta för kursdeltagaren att lära sig tillämpa ett vetenskapligt arbetssätt med hög kvalitet men på kort tid. Kursmålet är att utveckla och träna intellektuella färdigheter i vetenskaplig metodik. Målet ska uppnås genom att kursdeltagaren aktivt övar att tillämpa grundbegrepp och principer i praktikfall.
Den bärande idén bakom kursen är att utvecklingsarbetet i Försvarsmakten bör kvalitetssäkras genom att tillämpa vetenskaplig försöksmetodik vid kritiska moment i utvecklingsprocessen. Inriktningen på kursen och kompendiet överensstämmer med Alberts och Hayes’ (2002) ”Code Of Best Practice in Experimentation” för att stärka den försöksmetodiska kompetensen i USAs försvarsmakt. I jämförelse med deras orienterande handbok för COBP går kompendiet längre i att förbereda för praktisk försöksverksamhet – i anslutning till kursdeltagarnas egna utvecklingsprojekt.
Det ersätter inte de övriga metodböckerna av Graziano och Raulin, Silverman samt Alberts och Hayes i den övriga kurslitteraturen men ger vägledning om hur man ska orientera sig effektivt inom det vidsträckta metodiska kunskapsfältet. Att behärska grundbegreppen och de elementära metodprinciperna är en absolut nödvändighet för att kunna tillämpa vetenskaplig metodik i praktiska sammanhang. Kompendiet kompletterar dessutom den övriga kurslitteraturen genom att ge en introduktion till de speciella teoretiska och metodiska problem, som uppstår i försöksverksamhet med komplexa system.
Referenser
Alberts, D. & Hayes, R. (2002). Code of Best Practice for Experimentation.
DoD Command and Control Research Program, Washington: CCRP publication series
Graziano, A. & Raulins, M. (2000)*. Research Methods. A process of inquiry.
4.ed. Boston: Allyn and Bacon.
Harré, R. (2002). Cognitive Science: A Philosophical Introduction.
London: Sage.
Hartley, P. (1999). Interpersonal Communication. 2nd ed. London:
Routledge.
Korman, A. (1977). Organizational Behavior. Englewood Cliffs.
Prentice-Hall.
Mohr, L. B. (1992). Impact Analysis for Program Evaluation. London: Sage.
Myrdal, G. (1968). Objektivitetsproblemet i samhällsforskningen. Stockholm:
Rabén och Sjögren.
Schein, E. H. (1988). Organizational Psychology, 3rd ed. Englewood Cliffs:
Prentice-Hall.
Silverman, D. (2001). Interpreting Qualitative Data. Methods for Analysing
Talk, Text and Interaction, 2nd ed. London: Sage.
Yin, R. (2003). Case Study Research. Design and Methods, 3rd ed. London:
Sage.
* Sidreferenserna i kompendiet till Graziano och Raulin avser 4. upplagan, 2000. Senare upplagor, t.ex. 7. upplagan 2010, har i allmänhet samma kapitelinnehåll men annan sidnumrering.
________________
1. INLEDNING
Tro, vetande och värderingar
I forsknings- och utvecklingsarbete likaväl som i den dagliga praktiska verksamheten har man ofta behov av att skilja mellan tro, vetande och värderingar. Vetenskaplig metodik är en produkt av människans strävan av att få en säker grund för att förstå och forma tillvaron i enlighet med vissa behov och värderingar. Framväxten av den moderna vetenskapen belyser många av hindren för en sådan strävan. Graziano och Raulin (2004, kap 1) beskriver den fascinerande historiska bakgrunden till den s.k. vetenskapliga revolutionen, som inleds på 1600-talet. Modern vetenskap bygger på en intrikat förening av rationella och empiriska principer och metoder. Rationalism innebär att utveckla kunskap genom resonerande och logisk slutledning, medan empirism inbegriper kunskaps-inhämtande genom att observera med hjälp av våra sinnen. Redan omkring 600 f.Kr. lades denna grund för västerländsk filosofi och empirisk vetenskap i Grekland (den för-Sokratiska perioden). Den försvagades senare av spekulativa filosofiska ansatser (särskilt Platons) av abstrakt, rationell karaktär, där den empiriska prövningen av kunskapen nedvärderades. Denna inriktning förstärktes under de närmaste tusen åren i Väst genom att den kristna religionen övertog rollen som auktoritet, när det gällde att förklara tillvarons villkor. Nya empiriska rön fick inte motsäga teologiska dogmer, och de fick dessutom bara användas i religionens tjänst. Starka värdesystem utvecklades i anslutning till dessa dogmer.
Under renässansen försvagades kyrkans grepp, särskilt som en följd av empiriska upptäckter, och den moderna naturvetenskapen växer fram. Dess mål är att förklara och förutsäga fenomen i verkligheten med hjälp av rationella medel (teori och logik) i kombination med empiriska metoder. Empirisk prövbarhet av påståenden om verkligheten är det avgörande kriteriet på en naturvetenskaplig ansats. Påståenden om verkligheten ska formuleras som empiriskt prövbara hypoteser för att man ska kunna avgöra deras sanningshalt. Eftersom målet är att upptäcka universella naturlagar, så är kunskapen om dessa värderingsfri.
Upptäckten av universella naturlagar medförde att olika teknologier kunde utvecklas, med enorma praktiska konsekvenser. Teknologiutvecklingen bidrog i sin tur till en allt snabbare vetenskaplig utveckling genom bl.a. konstruktion av tekniska instrument. Instrumenten innebär exempelvis att man blir mindre beroende av mänskliga sinnesbegränsningar och kan förbättra observations-tekniken. Det innebär samtidigt att det subjektiva inslaget i observationerna kan reduceras eller t.o.m. elimineras. En strängt objektiv vetenskaplig metodik blev möjlig.
Det naturvetenskapliga paradigmet blev förebild för utvecklingen av andra vetenskaper. Inom beteendevetenskapen är det särskilt psykologin, som har en naturvetenskaplig grundansats, även om behovet av att vidareutveckla denna har vuxit sig allt starkare. Även inom samhällsvetenskaperna dominerar vissa grundprinciper från det naturvetenskapliga paradigmet. Den naturvetenskapliga ansatsen är emellertid ifrågasatt inom delar av beteende- och samhällsvetenskap. Enkelt sammanfattat finns det åtminstone två typer av invändningar. Den ena argumenterar utifrån att man har skilda studieobjekt, som kräver olika ansatser. Exempelvis begrepp som ’mening’, ’avsikt’, ’kultur’ anses ofta av principiella skäl inte vara tillgängliga för fruktbara studier med en naturvetenskapligt grundad metodik.
En annan, delvis besläktad typ av invändning gäller kravet på objektiva och värderingsfria resultat eller fakta. Gunnar Myrdal (1968, s.52) hävdade att samhällsvetenskaplig forskning inte kan vara objektiv i traditionell mening: ”Tvärtom, varje undersökning av ett socialt problem – om än aldrig så begränsat i sin omfattning – är och måste vara bestämd av värderingar.”. …”Det enda sättet att sträva efter ”objektivitet” i teoretisk analys är att lyfta fram värderingarna i fullt dagsljus, göra dem medvetna, specifika och explicita och öppet klarlägga hur de bestämmer den empiriska forskningen.”
I det här sammanhanget bör man också nämna ansatser eller skolbildningar, som avviker från en traditionell, naturvetenskapligt färgad vetenskapssyn men är väletablerade inom många humanvetenskaper. Ett känt exempel är hermeneutik, tolkningskonst, som förekommer i olika former, mer eller mindre förenliga med traditionell vetenskap vad gäller gränsdragning och definitioner av ”tro, vetande och värderingar”.
Man bör också ibland vara beredd på att möta extrema avvikelser från ett traditionellt vetenskapligt synsätt. Exempelvis två feministsociologer, Stanley och Wise, har beskrivit begreppet ’objektivitet’ på följande sätt:
– ”an excuse for a power relationship every bit as obscene as the power relationship that leads woman to be sexually assaulted, murdered and otherwise treated as mere objects. The assault on our minds, the removal from existence of our experiences as valid and true, is every bit as questionable.” –
Silverman (s.220) refererar kritiskt Stanley och Wise’s argument att mansdominerade versioner av vad ’objektivitet’ innebär bör ersättas med giltiga beskrivningar av kvinnans verkliga ”upplevelser”. Författarna hävdar att forskningsmålet inte är att ackumulera kunskap utan att tjäna den kvinnliga emancipationen. Exemplet illustrerar att synen på värderingarnas roll kan variera drastiskt, om man går vid sidan av huvudfåran i vetenskapen.
I den praktiska verkligheten är gränserna mellan vad som är tro och vetande naturligtvis flytande och beroende av sammanhanget. Vetandet eller kunskapen omfattar många tveksamma ”sanningar” som är allmänt vedertagna utan att vara kontrollerade eller som grundas på intuition eller på att någon auktoritet uttalat dem. Detta innebär givetvis inte att den ”ovetenskapliga” kunskapen är oanvändbar. Tvärtom använder vi alla i vardagslag övertygelser och kunskap, som oftast inte är rationellt eller empiriskt motiverade utifrån vetenskap eller beprövad praxis.
ÖB tar i sin aktuella bok till Försvarsmaktens personal upp ett i detta sammanhang relevant problemområde: ”Min vision om Försvarsmakten i framtiden innehåller också klara ställningstaganden när det gäller människovärde och ledarskap. Jag kan inte under några som helst omständigheter acceptera att människor i Försvarsmakten kränks eller trakasseras. Detta hör inte hemma i Försvarsmakten.” (ÖB, 2004, s.47)
ÖBs grundvärdering delas förhoppningsvis av alla i Försvarsmakten. Men hur ska man hantera fenomenen ’trakasserier’ och ’kränkningar’ i praktiken? Arbetsmiljöverket har en särskild föreskrift om Kränkande särbehandling (ASF 1993:17). Men dess användning vid arbetsmiljöinspektionens tillsyn av arbetsplatser har kringgärdats med många förbehåll och stor försiktighet. Skälet har att göra med den oklara distinktionen mellan ”tro och vetande” i dessa ärenden. Vilka krav ska man egentligen ställa på ”fakta” om dessa fenomen från ett vetenskapligt perspektiv eller ur rättssäkerhetssynpunkt? Krävs det någon form av registrering eller dokumentation, eller att minst två oberoende observatörer har bevittnat en incident? Spelar det någon roll vilken relation vittnena står i till de inblandade personerna? Kan man göra en tillförlitlig subjektiv bedömning av hur trovärdig en person är som anmält en kränkning? Räcker det med att personen säger sig ha ”upplevt” en kränkande behandling?
Distinktionen mellan tro och vetande blir ännu mer problematisk om man beaktar de tänkbara psykologiska processer som ligger till grund för upplevelser av händelsen. Offer, förövare och vittnen kan ha olika uppfattningar om vad som hänt. Det kan finnas olika dolda avsikter med att påtala en incident – eller att förneka den. Dessutom kan individens värdering av den specifika inträffade händelsen vara mer eller mindre konsistent med dennes principiella inställning till kränkningar.
Parentetiskt kan man notera att den bästa strategin är primärprevention, dvs. att stämma i bäcken, vilket uppenbarligen är ÖBs avsikt.
Graziano och Raulin (kap.1) betonar att vetenskaplighet är särskilt nödvändig inom psykologin, eftersom vi alla är en sorts amatörpsykologer, som inte alltid får våra felaktiga föreställningar om medmänniskor och tillvaron korrigerade. Särskilt viktigt är det att vetenskapen kan skydda oss mot pseudovetenskaplig psyk-logi.
Att använda ett vetenskapligt arbetssätt för praktisk problemlösning ställer verkligen krav på utövaren. Grundbegreppen och de övergripande metodprinciperna är lätta att tillägna sig. Det är i stället applikationen i praktiska sammanhang, som är svårigheten. Det gäller i synnerhet sociala och organisatoriska system. I fysiska-tekniska applikationer finns det ofta universella principer med vars hjälp man kan utarbeta detaljinstruktioner, som fungerar i skilda sammanhang. I sociala system ingår däremot människor med varierande kunskaper, övertygelser och värderingar. Det finns ett relativt fåtal universella principer, men att tillämpa dem kräver ofta att man måste ta hänsyn till en förskräckande mängd situationsbundna villkor. Konsekvensanalyserna blir då både logiskt, kunskapsmässigt och praktiskt komplicerade.
Osäkerhet om gränser mellan empiriskt grundade fakta, övertygelser och värderingar uppkommer praktiskt taget alltid i samband med komplicerat utvecklingsarbete. Begreppet ’NBF’ är ett exempel, där rågångarna mellan etablerade grundfakta, prognosticerade tillstånd och konsekvenser samt visioner är delvis flytande. Fakta, liksom övertygelser och värderingar av mål och medel hos aktörerna, ändras dessutom dynamiskt efterhand som utvecklingsarbetet fortskrider.
Begreppen tro, vetande och värderingar är alltså oklara och svåra att avgränsa från varandra. Som psykologiska fenomen hos den enskilde människan är de mer eller mindre oupplösligt sammanflätade. Men historien lär oss att det finns goda skäl att försöka göra gränsdragningar. I den moderna vetenskapen finns det definitioner och regler, som preciserar vilka krav man ska ställa på fakta och hypoteser och att tydliggöra antaganden i slutledningar. I svåra gränsfall räcker kanske inte detta regelsystem, men då finns i stället kravet på att redovisa sin forskningsprocedur så tydligt att kompetenta kolleger själva kan ta ställning till dess giltighet (jfr citatet av Myrdal tidigare).
__________
Kompendiet beskriver traditionell vetenskaplig metodik, dvs. har en pragmatisk, naturvetenskaplig ansats som förebild. Först behandlas grundbegreppen översiktligt. I den del som introducerar applikationer på komplexa systemproblem, så utvidgar vi sedan grundbegreppen med en del teoretiska och metodiska verktyg, som krävs för att hantera utvecklingsarbete och systemdesign.
2. GRUNDBEGREPP I VETENSKAPLIG METODIK
2.1 Allmän karakteristik
En forskare (Korman, 1977 s.17) har beskrivit grundprinciperna i vetenskaplig metodik på följande sätt:
(a) "Slutsatser, bedömningar och slutledningar grundas på empiriska observationer, inte på tro eller förhoppningar.
(b) Vetenskaplig forskning är målinriktad, inte slumpartad; dvs. det finns skäl till att vissa frågeställningar väljs ut för undersökning snarare än andra.
(c) Vetenskaplig forskning är kumulativ och självkorrigerande; den bygger på det föregående. 'De som inte känner till historiens misstag är dömda att upprepa dem'.
(d) En vetenskaplig undersökning är möjlig att upprepa; dvs. de procedurer, som använts, beskrivs så tydligt och klart att vilken annan kompetent forskare som helst skulle kunna upprepa undersökningen om hon/han så önskade.
(e) Vetenskaplig forskning är kommunicerbar; de begrepp och idéer som utnyttjas och studeras är inte av privat natur utan är av ett slag som i princip kan användas av alla kompetenta individer."
Korman säger också att principerna är ideal, som ibland överträds medvetet eller omedvetet. "De flesta beteendevetare försöker följa dessa principer, och när de gör det, blir den erhållna informationen mer tillförlitlig än information som erhållits på andra sätt".
Forskning är alltså en speciell form av problemlösning. Verktygen vid denna problemlösning är dels metoder för att samla in och testa information (empiri) och dels olika former av beskrivnings- och förklaringssystem (teorier, modeller) för att organisera och analysera informationen om de fenomen man studerar. Till de empiriska metoderna hör t.ex. direktobservation av händelser; ett annat exempel är intervjuteknik och frågeformulär för att försöka studera upplevelser och uppfattningar. De teoretiska beskrivningssystemen är vanligtvis konstruerade av precisa språkliga uttryck; beskrivningar i matematiska termer eller i form av datorprogram förekommer emellertid allt oftare.
Vilka krav på problemlösningen ska man ställa? Det finns regler knutna till varje fas i forskningsprocessen för att den skall ge resultat som dels är tillförlitliga (kravet på reliabilitet) och dels är välgrundade med hänsyn till problemet (kravet på validitet).
2.2 Faser i forsknings/utredningsprocessen i en enskild studie
Vi särskiljer följande faser i problemlösningsprocessen (se Figur 2.2): problemformulering, datainsamling, dataanalys, tolkning av resultat och kommunikation av information.
Den ursprungliga problemställningen kan vara uttryckt i klientens eller användarens språkbruk och perspektiv. Forskaren/utredaren måste förstå och respektera denna problemsyn – detta utgör grunden för det ”sociala kontrakt" som måste finnas mellan forskaren/utredaren och klienten.
På samma sätt skall slutsatserna senare kommuniceras med ett språk och en begreppsapparat som förstås av avnämarna. I faserna mellan dessa "ingångs- och utgångsvärden" preciseras och bearbetas problemet i en teknisk referensram, där fackspråket dominerar. Problemlösningsprocessen förutsätter att klienten eller användaren har förtroende för kompetens och forskningsetik hos forskaren och utredaren.
Vi skall bara ge en översiktlig skiss av faserna i forsknings- och utrednings-processen här, eftersom de kommer att övas senare under kursen i anslutning till olika praktikfall. I problemanalysen preciseras och formaliseras den ursprungliga problemställningen. Problemet avgränsas och bearbetas inom en given referensram, som bestäms både av det praktiska syftet med utredningen och med hänsyn till teori och kunskap inom problemområdet. Problemanalysen utmynnar i preciserade delfrågeställningar eller i form av hypoteser. (En hypotes är ett påstående, uttryckt som ett möjligt svar på en fråga.)
I nästa fas planeras en undersökning för att samla in information, så att frågeställningarna kan besvaras och hypoteserna prövas. När undersökningen genomförts, bearbetas data med statistiska, matematiska eller språkliga metoder, vilket leder till sammanfattande resultat – hypotesernas riktighet bekräftas eller förkastas. Resultaten tolkas slutligen i relation till den ursprungliga problemställningen samt tidigare kunskap och teori inom problemområdet.
Observera "ramen" kring faserna i Figur 2.2, som innebär att studien planeras och genomförs som en integrerad enhet. Även om faserna i verkligheten följer efter varandra i en bestämd kronologisk ordning, betyder inte detta att tidigare faser planeras oberoende av senare. Planeringen sker både som översiktsplanering och som detaljplanering av resp. fas. Översiktsplaneringen innebär att man samordnar olika faser i processen.
Figur 2.2. Faser i forsknings/utredningsprocessen.
2.2.1 Problemanalys
Den ursprungliga problemställningen är ofta oprecis och ger ingen direkt ledtråd om var eller hur man skall finna svaret. Syftet med problemanalysen är att på grundval av tillgänglig kunskap (bl.a. facklitteratur och eventuella förstudier) samt logiska överväganden komma fram till mer precist formulerade och lösbara problem.
Man kan skilja mellan innehållsliga och formella aspekter i problemanalysen. Låt oss se på några steg i den formella analysen:
Ett forskningsproblem definieras formellt som "en relation mellan två eller flera begrepp, uttryckt som en fråga". Antag att den ursprungliga problemställningen lyder på följande sätt:
"Vad påverkar lägesuppfattningen i en ledningsenhet i Försvarsmakten?"
Detta problem bör omformuleras för att uppfylla de logiska kraven. Ett av begreppen är naturligtvis "lägesuppfattningen", men vilket eller vilka andra begrepp bör ingå i forskningsproblemet? Den ursprungliga frågeformuleringen i termer av ”Vad?” är alldeles för allmän för att ge några riktlinjer för hur problemet ska undersökas. Problemet bör alltså avgränsas och struktureras för att man ska kunna komma fram till entydiga slutsatser. Ett vanligt sätt att strukturera problem är att formulera orsak-verkan-samband. Det förutsätter att man avgränsar en eller flera tänkbara orsaker och relaterar dem till en eller flera effekter. En lösare relation beskriver ingångs- och utgångsvärden (input/output): mängden X är input, och mängden Y är output av någon process.
Genom bl.a. litteraturstudier samt analys av förekommande praxis kommer vi kanske fram till en mängd olika faktorer, som kan påverka lägesuppfattningen. Den ursprungliga problemställningen kan t.ex. ha ett underförstått fokus på att lägesuppfattningen är resultatet av en informationsinhämtning; det kan ge oss en vägledning om att avgränsa problemet till att först kartlägga sambandet mellan lägesinformation och lägesuppfattning, dvs. en sorts input/output-relation kan vara lämplig.
Grundproblemet kan alltså avgränsas och formuleras så att det uttrycker en formell relation mellan två begrepp, typer av lägesinformation (X) och lägesuppfattning (Y), t.ex:
"Vilken lägesinformation påverkar lägesuppfattningen?"
Vi kan också formulera om problemet till en allmän hypotes. Hypoteser kan alltid skrivas om till formen "Om X, så Y" (den s.k. generella implikationsformeln, som ofta skrivs X→Y). I vårt fall blir hypotesen:
"Om viss lägesinformation X förekommer, så påverkas lägesuppfattningen Y."
Observera att det är "relationen" mellan begreppen, som är bärare av information (ny kunskap) och har "förklaringsvärde" i detta fall. Det är viktigt att också göra klart för sig logiskt vad hypotesen inte uttrycker. I princip kan exempelvis en lägesuppfattning uppkomma, utan att ha samband med någon tydlig informationskälla.
Den allmänna hypotesen är i sig redan en avgränsning av den ursprungliga problemställningen. Den kan specificeras ytterligare genom att formulera en rad del- eller underhypoteser.
För att hypoteser skall bli prövbara måste emellertid begreppen och relationen preciseras genom definitioner. Vad menas egentligen med "lägesinformation" och "lägesuppfattning"? De språkliga termerna är ofta oprecisa och uppfattas olika av olika människor.
Det finns två huvudtyper av definitioner:
(a) att precisera den allmänt förekommande betydelsen av en term (deskriptiv definition). Ett exempel på en sådan definition är:
’Lägesinformation'=def ”Information avseende aktörer, miljö och resurser med deras egenskaper som geografisk position, status, pågående verksamhet, lydnadsförhållande, senast erhållet uppdrag/ order och/eller syftet med agerandet, samt information avseende miljön (terräng, väder, sikt och ljusförhållanden). Lägesinformation kan vara historisk, aktuell eller planerad/ prognosticerad.”
(b) att tilldela en ny eller gammal term en speciell betydelse (stipulativ definition). Ett exempel på en sådan definition är: "’Lägesuppfattningen’ undersöktes genom att deltagarna i undersökningen fick producera en individuell grafisk lägesbild med hjälp av ett givet symbolspråk.”
Vidare bör begreppen ha en klar logisk form. Vetenskaplig begreppsbildning använder sig av två viktiga typer:
(a) Klassifikationsbegrepp. Begreppet består då av olika kvalitativa aspekter eller klasser, t.ex. begreppet kön med klasserna kvinnligt (K) och manligt (M). Klasserna skall vara ömsesidigt uteslutande (K ≠ M) och uttömmande (inga andra klasser kan vara definitionsmässigt möjliga - men kan ändå förekomma i verkligheten! ). I vårt exempel är det angeläget att konstruera en lämplig klassifikation av olika typer av lägesinformation med utgångspunkt från definitionen tidigare.
(b) Kvantitativa begrepp. Dessa förutsätter att en variation i mängd eller grad är möjlig. Ett kvantitativt begrepp utgör följaktligen en variabel. Exempelvis mängden lägesinformation av viss typ skulle kunna betraktas som ett kvantitativt begrepp.
Begreppsbildningen måste grundas på en innehållslig analys med hänsyn till existerande kunskap, teori samt naturligtvis syftet med studien. Man måste i varje undersökning ta ställning till om man skall använda existerande begrepp och definitioner eller utveckla nya och bättre. I allmänhet försöker man bilda begrepp och hypoteser, som har hög generalitet och förklaringsförmåga, men ändå tillfredsställande precision. Den innehållsliga analysen bestämmer också om hypotesen skall uttrycka enbart ett statistiskt samband mellan begreppen eller en starkare kausal relation (orsak-verkan).
Ta t.ex. begreppet "lägesinformation", som är generellt. För att formulera precisa frågor eller hypoteser fordras det att man specificerar underbegrepp. Exempel på sådana framgår av den tidigare definitionen, som i praktiken är en form av klassifikation. Ibland kan man nöja sig med att söka fastställa ett enkelt samband mellan X (lägesinformation) och Y (lägesuppfattning). Förklaringsvärdet vad gäller relationen mellan ’lägesinformation’ och ’lägesuppfattning’ är däremot fortfarande minst sagt oklart: Hur kan lägesinformationen påverka lägesuppfattningen? För att förklara det behöver vi uppenbarligen specificera en rad ytterligare begrepp, t.ex. den uppgift eller roll, som ledningsenheten har. Den rollen är i sin tur beroende av andra organisatoriska funktioner, t.ex. om det gäller en centraliserad eller decentraliserad bearbetning av lägesinformationen osv. Problemanalysen kan avslöja en rad oklarheter i begreppen och deras relationer, även om man vid första påseende kan tycka att det är mer eller mindre självklart att en viss lägesinformation bidrar till lägesuppfattningen på ett visst sätt.
Ett exempel på ett något mer utvecklat sådant hypotetiskt samband är: ”Lägesinformation av typ XT för att lösa en viss uppgift XU förbättrar lägesuppfattningen Y” (se streckad linje i Figur 2.2.1) Av flera skäl bör man emellertid fördjupa problemanalysen på denna punkt. Vad ligger bakom ”förbättringen”? Det finns troligen också många undantag från hypotesen om ett enkelt samband, vilket kan tyda på att andra faktorer ”modererar" påverkanseffekten av lägesinformation. Vad har man egentligen förklarat genom att påvisa ett måttligt samband mellan X (XT & XU) och Y?
Om man i stället formulerar en hypotes om att det finns en kausal relation mellan en eller flera riskfaktorer (orsaker) och ledningsuppfattning (verkan), så förutsätter man någon slags process eller mekanism, som förklarar påverkan från X till Y. I Figur 2.2.1 är det hypotetiska processbegreppet betecknat med P. Vi behöver alltså specificera ett nytt inskjutet processbegrepp "P" med de relationer, som markeras av pilarna i figuren. Ett exempel på ett sådant begrepp eller mekanism är någon form av "bedömningsprocesser". Resonemanget leder alltså till en mer specifik hypotes om att viss lägesinformation i en given uppgift eller roll förbättrar ledningsuppfattningen, tack vare att bedömningarna kan ske på ett visst effektivt sätt.
Figur 2.2.1. Exempel på problemanalys.
Det resonemang som vi har fört illustrerar begreppsbildningens roll vid problemanalys och skulle kunna vara början till en modell av lägesbedömningar. Modellen kan utvecklas till en teori, som innebär ett system av begrepp och relationer mellan dem, som har prövbara konsekvenser (formulerade som hypoteser).
Den första faktorn eller begreppet (X) i hypotesen "Om X, så Y" kallas ofta för oberoende variabel, medan faktorn Y kallas beroende variabel. I hypoteser om kausala relationer är den oberoende variabeln alltid identisk med orsaksfaktorn och den beroende variabeln uttryck för dess verkan. I hypoteser om samband är denna distinktion inte lika "naturlig", utan vad som är oberoende resp. beroende variabel beror på undersökningens syfte och kan alltså variera från tillfälle till tillfälle.
Det är givetvis också möjligt att formulera och undersöka mer komplexa hypoteser som inrymmer flera oberoende variabler t.ex. "om X, Z, V, så Y". Ett exempel på en mer komplicerad design är om vi vill undersöka både de specifika och kombinerade effekterna av XT och XU på Y: dvs. XT × XU→Y.
Hypotesprövningens grundlogik
En hypotes i ett experiment är ett påstående om ett visst experimentresultat eller utfall Y, givet en förutsättning X. En enkel kausal hypotes H är H: X→Y (X orsakar Y). Den implicerar logiskt att om X förekommer, så ska Y inträffa. Om Y inte inträffar, så är följaktligen hypotesen H falsk.
Hypotesprövning förutsätter alltså ett utfallsrymd, där det finns ömsesidigt uteslutande utfall, som antingen bekräftar eller falsifierar hypotesen. I exemplet ingår de två alternativen Y respektive icke-Y i utfallsrymden).
Slutledningen har en bestämd logisk form (Modus ponens) som omfattar tre led:
1. Teoretisk premiss: H: X→Y
2. Empirisk premiss: X
3. Slutledning om empiriskt utfall: Y
I experimentella undersökningar förutsätter hypotesprövningen således att en specifik hypotes formuleras (teoretisk premiss), och att man konstruerar en faktisk undersökningssituation, som uppfyller de logiska och teoretiska kraven på dels X (empirisk premiss) och dels Y (empirisk konsekvens som motsvarar den logiska slutsatsen).
Hypotesprövningen förutsätter logiskt att det finns en kontrast till X, dvs. icke-X, och en kontrast till Y, dvs. icke-Y. Undersökningsmetodiken måste utformas på så sätt att de logiska villkoren uppfylls i undersökningsdesignen. Detta innefattas under begreppet kontroll. Se vidare kapitel 8 om hypotesprövning i Graziano och Raulin.
2.2.2 Undersökningsmetodik
Utgångspunkten vid val av undersökningsmetod är alltså ett problem eller alternativt en hypotes, som uttrycker en relation mellan två eller flera variabler (faktorer), och där oberoende och beroende variabler är definierade. Undersökningsplanering innebär att hypotesen (problemet) översätts till empiriska operationer. Begreppen blir följaktligen operationellt definierade (se Figur 2.2.1). Det är uppenbart att det i princip finns ett oändligt antal möjligheter att operationalisera begreppen. Valet av undersökningsbetingelser styrs till viss del av hur hypotesen är formulerad. En hypotes med väldefinierade, precisa begrepp är lättare att pröva entydigt, medan en oklar frågeställning lämnar föga vägledning vid undersökningsplaneringen.
Vilka krav skall man ställa på en bra undersökningsmetod? Frågan har berörts tidigare, och svaret är att metoden skall ge information som har hög reliabilitet och validitet. Reliabilitet betyder tillförlitlighet och innebar frånvaro av slumpmässiga (osystematiska) fel vid undersökningen. Metoden måste alltså minimera tillfälligheternas spel i undersökningssituationen.
Validitet innebär frånvaro av systematiska fel i resultaten. Vi behöver särskilja några olika typer av validitet: Begreppsvaliditet gäller frågan om hur väl de operationella definitionerna överensstämmer med de teoretiska begreppen. I vårt exempel gäller det hur pass väl de faktiska undersökningsmetoderna att beskriva och observera lägesinformation, bedömningsprocesser och lägesuppfattning stämmer överens med motsvarande teoretiska begrepp (X, P, Y).
Varje undersökning/utredning måste granskas med avseende på hur olika faktorer kan påverka resultatet. Skälet härtill är att man vill kunna avfärda alternativa förklaringar till resultat, som inte inryms i hypotesen. Förfarandet avser att fastställa den interna validiteten i resultaten. En mängd olika faktorer i och vid sidan av bedömningssituationen kan spela in och påverka lägesuppfattningen. Om man är intresserad av pröva exempelvis en specifik hypotes om hur lägesinformation påverkar lägesuppfattning, så måste dessa andra ovidkommande faktorer kontrolleras. Annars kan man av logiska skäl inte pröva hypotesen. Resultatet saknar då intern validitet.
En undersökning/utredning ska inte bara ha en riktig logisk uppbyggnad, utan den bör också ge resultat som kan generaliseras till andra tider, situationer, individer, arbetsuppgifter och organisationer än de som ingått i undersökningen. Detta gäller kravet på extern validitet (generaliserbarhet).
Insamlandet av information måste därför ske under väl kontrollerade former för att undvika olika typer av felkällor och felaktiga slutsatser. Graden av kontroll över felkällor varierar med typ av undersökningsmetodik. Ju fler kontrollrestriktioner man kan införa i undersökningen, desto lättare är det i allmänhet att pröva kausala hypoteser (Graziano och Raulin, kap.2).
Experimentell metodik används främst för att pröva hypoteser om kausala relationer. Det utmärkande för experimentell metodik är att forskaren aktivt manipulerar en eller flera oberoende variabler (OV) för att studera effekter på beroende variabler (BV). Tre typer kan särskiljas: (a) "Äkta" experiment (oftast laboratorieförsök), där man fördelar deltagare (eller motsvarande enheter) slumpmässigt på de olika betingelser som OV består av. (b) Kvasiexperiment (oftast fältförsök), då kravet på slumpmässig fördelning av deltagare eller enheter inte kan tillgodoses, utan fördelningen måste styras utifrån någon given, naturlig princip (t.ex. befattning, avdelningstillhörighet); (c) Simuleringsexperiment (egentligen en kombination av a och b), då man i laboratorieform försöker konstruera verklighetstrogna uppgifter och situationer.
Icke-experimentell metodik (ibland kallad korrelationsmetodik) används då oberoende variabler inte kan manipuleras aktivt. I allmänhet (men inte nödvändigtvis) är undersökningssituationen även i övrigt under sämre kontroll än vid experimentella studier. Det är i princip möjligt att undersöka kausala relationer också med icke-experimentell metodik; tillvägagångssättet blir dock mer indirekt och resultatet betydligt osäkrare än vid experiment.
Fallstudie är enligt Yin (2003, s.13) en empirisk undersökning som undersöker ett samtida fenomen i dess verkliga sammanhang (kontext), speciellt när gränserna mellan fenomenet och kontexten inte är tydliga. Den kvalificerade fallstudien styrs teoretiskt och använder multipla datakällor i situationer, där det finns fler variabler än datapunkter.
Aktionsforskning är en speciellt utvecklad form av vetenskaplig metod för att möjliggöra kontrollerade interventioner i sociala system (t.ex. arbets-organisationer). Aktionsforskning liknar experiment så till vida att forskaren (förändringsagenten) aktivt intervenerar i undersökningssituationen. Till skillnad från fallet i experimentella studier utgör de "oberoende variablerna" här komplexa skeenden i naturliga miljöer, vilket medför starkt begränsade möjligheter att kontrollera felkällor.
Undersökningsplanering utmynnar i en plan (design) för hur data skall insamlas. Där specificeras bl.a. de oberoende och beroende variablerna, olika åtgärder för att kontrollera effekten av ovidkommande faktorer samt naturligtvis de tekniker, som används för registrering, klassifikation och mätning av data.
Undersökningsteknikerna omfattar bl.a. systematiska och deltagande observationer samt olika former av objektiva och subjektiva mätinstrument för att studera händelser och beteenden. Upplevelser, attityder m.m. studeras vanligen indirekt genom intervjuer, frågeformulär, subjektiva bedömningar och olika tester. Dessutom finns icke-reaktiva tekniker, där deltagarna inte kan reagera på undersökningsmetoden. Dit hör bl.a. studier av arkivdata, vissa fysiska registreringar och analyser av produkter eller spår av beteenden och händelseförlopp.
__________
Övriga faser i forsknings/utredningsprocessen kommer vi att behandla i anslutning till olika praktikfall.
2.3 Sammanfattande beskrivning av vetenskapligt paradigm
Figur 2.3 illustrerar relationen mellan beskrivningssystem och empiriskt system, dvs. empiriska händelser och objekt. Avbildningen av det empiriska systemet beror på hur man väljer empiriska metoder och sätt att beskriva logiska nätverk av hypoteser om begreppsrelationer. Ett vetenskapligt paradigm föreskriver hur detta bör gå till.
Figur 2.3.1 Relationen beskrivning – empiriskt system.
Figur 2.3.1 ger en översiktsbild av vilka frågor, som bör ställas för att få en uppfattning om den vetenskapliga ansatsen. Schemat är konstruerat mot bakgrund av en naturvetenskaplig grundansats. Figuren visar hur paradigmet påverkar problemval, planering, genomförande och slutsatser av en studie. Figur 2.3.2 ger en schematisk bild och exemplifiering av vad som kännetecknar god metodik vid empirisk prövning av hypoteser.
Begreppsligt plan. Ett paradigm ger svar på frågor om hur man väljer beskrivningssystem:
1. Valet beror i första hand på vilka undersökningsobjekt och händelser i verkligheten det gäller. Det kan exempelvis vara sociala system, komplexa förlopp, upplevelser osv.
2. Syftet med studien eller projektet är viktigt. Handlar det t.ex. om att upptäcka och förklara skeenden som orsak-verkan-samband? Eller är uppgiften att förändra och designa verksamheter för att nå vissa mål?
3. Förekommer olika aspekter på ”tro, vetande, värderingar” i uppgiften och kan och bör dessa hållas isär eller ej?
4. Vilka beskrivningsformer är lämpliga? Alternativa former är t.ex. naturligt språk, bilder och grafik eller formella symbolspråk (matematik, logik, programkoder etc.)
5. Vilka ämnesteorier och principer är relevanta för studien?
Empiriskt plan. Undersökningsobjekt och faktorer kan gälla mikro- eller makrovärldar. Distinktionen mellan mikro och makro är relativ men påminner oss om att makrobeskrivningar ibland kan reduceras till mikronivå, t.ex. från beteenden till neurala och muskulära processer. Omvänt kan beskrivningar på detaljnivå ibland sammanfattas på makronivå. Exempelvis relationen mellan fysiska spår och produkter av en verksamhet samt beteenden kan beskrivas sammanfattade i makroorganisatoriska termer.
Ett empiriskt plan omfattar också metoder och interventioner, dvs. empiriska operationer för att undersöka, bedöma, manipulera undersökningsobjekt och händelser.
Kopplingen mellan begreppsligt och empiriskt system. Två viktiga aspekter på kopplingen är:
– att den begreppsliga beskrivningen är en avbildning eller kunskapsrepresentation av empirin,
– att begreppssystemet krävs för att ta fram ny empiriskt grundad kunskap i syfte att beskriva och förklara verkligheten och för att manipulera verkligheten (genom intervention och design).
Vetenskaplig kunskap är en produkt av rationalism och empirism (Graziano och Raulin, kap. 1). Verifikationen av påståendekunskap kräver att påståenden (hypoteser) kan kategoriseras som sanna eller falska och att metoden för den empiriska prövningen måste beaktas.
Principerna för ”god metodik” i en naturvetenskaplig grundansats illustreras i Figur 2.3.1. Idéer i begreppslig form bildar hypoteser, dvs. generella påståenden om empiriska företeelser. Uppslaget till hypoteser kan ibland härledas deduktivt från en teori, men bygger ofta på en induktiv generalisering, dvs. på erfarenhets-baserade slutsatser. En generell hypotes kan inte prövas direkt, utan den kräver att man härleder mer specifika, prövbara hypoteser. Figur 2.3.2 är ett exempel på nätverk av implikationer (härledda hypoteser) på olika abstraktionsnivåer.
Figur 2.3.1. Hur paradigmet påverkar problemval, planering, genomförande och slutsatser av en studie.
Observera att hypotesprövning om empiriska förhållanden förutsätter att man gör slutledningar enligt logiska regler. De logiska villkor som måste uppfyllas för att ett påstående ska kunna kategoriseras som sant eller falskt måste i sin tur ha en motsvarighet på det empiriska planet (se 2.4).
Man inser lätt att en generell hypotes som genererar många implikationer (hypoteser), varav ett flertal bekräftas, ger en god teoretisk beskrivning av verkligheten. En generell hypotes kan ej logiskt bevisas vara sann, eftersom ett oändligt antal prövningar är möjliga i princip. Någon följdhypotes i framtiden kan visa sig ge motstridigt resultat, vilket då innebär att den generella hypotesen måste förkastas eller åtminstone modifieras. Detta är grunden till att teorier och universella hypoteser ständigt förändras till följd av empiriska prövningar och att man konstruerar nya begreppsmodeller.
Paradoxalt nog kan man inte logiskt bevisa att en universell hypotes är sann men däremot att den är falsk – om nämligen en logisk följdhypotes inte bekräftas. Filosofen Karl Popper har hävdat att vetenskapen utvecklas genom att förkasta inadekvata hypoteser om verkligheten.
Empiriska fakta utgör den stabila grunden. De logiska villkoren för en prövning beskrivs i specifika, datanära forskningshypoteser. I Figur 2.3.2 gäller det hypoteserna närmast det empiriska planet. Det empiriska resultatet eller utfallet av en prövning ska i princip vara entydigt och faktiskt och ge svar på frågan om den specifika hypotesen är sann eller falsk. Sensmoralen är att om forsknings-hypotesen är tillräckligt specifik och datanära, så kan man få ett entydigt svar på om den är sann eller falsk. Ytterst är det alltså sådana specifika empiriska prövningar som ska avgöra om en generell hypotes ska bekräftas, dvs. få stöd eller förkastas.
Hur används 'Vetenskaplig metodik' för att ge svar på frågor av typen:
(1) kan en händelse ha inträffat på det sätt som framgår av en beskrivning (data)?
(2) Kan händelsen förklaras med hjälp av accepterade teorier och kända fakta eller måste den tidigare kunskapen modifieras?
Figur 2.3.2 illustrerar principer för empiriska prövningar.
Figur 2.3.2. Schematisk bild av empirisk prövning.
Sammanfattningsvis, generella hypoteser uttrycker preliminär kunskap, medan empiriska fakta, uttryckta som specifika hypoteser, utgör stabila men begränsade kunskapselement.
Till beskrivningen ovan av vetenskaplig metodik måste fogas två reservationer. En är att sant-falskt-logiken i slutledningar i allmänhet måste kompletteras med sannolikhetsbeskrivningar. En hypotes är alltså sann eller falsk med en viss sannolikhet. Det grundläggande resonemanget förändras emellertid inte av detta. I praktiken innebär det att statistiska beskrivningar och bedömningar måste komplettera det logiska resonemanget. Den andra reservationen gäller den empiriska metodiken. Alla slutsatser om hypotesprövning är naturligtvis beroende av att man använt en adekvat metodik och kontrollerat felkällor etc.
2.4. Begreppet ’kontroll’
’Kontroll’ är ett fundamentalt begrepp i vetenskapen. Det står för de empiriska villkor som måste vara uppfyllda för att man ska kunna göra giltiga slutledningar om att utsagor är sanna eller falska (eller har sannolikheter för detta). ’Kontroll’ är alltså de empiriska operationer eller villkor som svarar mot de logiska villkoren vid hypotesprövning.
Kontroll av variation. Vi ska utveckla kontrollbegreppet i anslutning till några enkla exempel. Anta att vi vill utvärdera prestationen hos ett speciellt förband med ny organisation X. Vi betecknar prestationen med Y. En empirisk prövning av förbandets prestation utförs och ger resultatet Y1. Om vi har någon form av prestationsnorm Yk, kan vi jämföra prestationen med normen och dra en direkt slutsats om prestationen var tillräcklig eller ej.
Y kan vara antingen en kvalitativ eller kvantitativ faktor, t.ex.
– Y1 skiljer sig kvalitativt från Yk
– Y1 uppfyller inte det kvalitativa kravet Yk
– Y1 är en kvantitativt lägre prestation än Yk
De tre påståendena kan vara hypoteser med sanningsvärdena ”sant” eller ”falskt”.
Vid tillfället t1 kan vi i princip avgöra om respektive påstående är sant eller falskt. Det förutsätter naturligtvis att vi kan identifiera X och Y-faktorerna i verkligheten. Vi måste med andra ord ha någon slags rudimentär kontroll över undersökningssituationen.
Frågan är emellertid om vi kan generalisera resultatet till andra tillfällen, situationer och deltagare. Eller var resultatet en tillfällighet vid denna tidpunkt och plats och med dessa deltagare i förbandet? Eftersom det handlar om ett komplext, socialt och tekniskt system, måste vi räkna med en osäkerhet i prestationen, som beror på en mängd svårkontrollerade förhållanden.
Ett naturligt sätt att skaffa sig en uppfattning om osäkerheten i resultatet är att upprepa försöket ett antal gånger,
(Y1), Y2, Y3, … Yi, …Yn.
En estimation eller skattning av ett väntevärde (det statistiska gränsvärde som uppkommer om försöket skulle upprepas ett oändligt antal gånger) blir då möjlig, t.ex. genom att beräkna proportionen kvalitativt godtagbara resultat,
pY = fy/n,
dvs. antal godtagbara prestationer (fy) dividerat med antal upprepade försök (n). Alternativt kan prestationen Y vara en kvantitativ variabel (ett prestationsmått) och ett medelvärde beräknas av Yi,
MY=ΣYi/n,
där summan av prestationerna (1 … n) divideras med antalet försök.
Dessutom blir det möjligt att beräkna ett osäkerhetsområde – spridningsmått Spy eller SMy – för variationen kring pY respektive MY. Ju fler försök som görs, desto säkrare blir skattningen av väntevärdet p eller M och deras spridningsmått.
Två exempel på resultat visas i diagrammen nedan. I det vänstra diagrammet med ett kvalitativt procentkriterium Yk är pY = 0.60. I det högra diagrammet med ett kvantitativt prestationsmått är MY= 3,55 Om Yk≥3,50, så finns det också här 60% godtagbara försök.
Procent godtagbara försök Antal försök med Y=1...5
Kvalitetskrav Yk Prestationsmått Y
”Kontrollen” i exemplet innebar att X, dvs. förbandsorganisationen, hölls konstant, samt att observationen av Y gjordes på samma sätt vid upprepade försök. Utan denna konstanthållning hade man inte kunnat dra någon generell slutsats alls om X. (Detta gäller när man prövar universella [generella] hypoteser, ”Det gäller för alla X att om X så Y”. En existentiell hypotes, ”Det gäller för åtminstone ett X att om X så Y”, kräver däremot bara ett enda positivt utfall för att hypotesen ska bekräftas.)
Den fortsatta utvecklingen av ett X-system – om resultatet bedöms som lovande – kan då inriktas på att dels försöka minska den störande ”felvariationen” (Spy, SMy), dvs. kontrollera olika störfaktorer som skapar den slumpmässiga variationen i Y, och att dels systematiskt förbättra prestationen Y (dvs. öka pY, MY).
När det gäller tekniska eller fysiska krav, kan en sådan försöksuppläggning ofta vara tillfyllest. När det gäller komplexa sociala system, ställs det i allmänhet betydligt större krav på kontroll.
Kontroll genom att använda kontrasterande betingelser. I det förra exemplet var betingelsen X (ny förbandsorganisation) given och utvärderades mot en prestationsnorm. Oftast saknas en enda entydig norm, och det finns en rad olika krav eller kriterier på prestationen. Under sådana omständigheter behöver man pröva sig fram genom att jämföra eller kontrastera olika alternativ. Vanligen existerar oftast alternativa betingelser, t.ex. en redan existerande förbands-organisation. Många gånger är alternativet till X logiskt underförstått; exempelvis kan hypotesen ”Om X, så Y” implicera att om X inte inträffar, dvs. ”icke-X”, så ska ”icke-Y” inträffa, dvs. X är en nödvändig betingelse för Y.
Prövningen kan då formuleras som en jämförelse mellan två eller flera betingelser, XA, XB, … XJ. Den gamla organisationen XB blir en kontrollbetingelse till den nya organisationen XA och deras prestationer jämförs under i övrigt samma villkor. Observera att begreppet ’kontroll’ nu har två olika funktioner:
(a) Kontroll av den oberoende betingelsen (variabeln), dvs. kontrasten mellan betingelserna XA och XB i det här fallet.
(b) Kontroll av ovidkommande (störande) betingelser, dvs. variabler Z som påverkar XA och XB på olika sätt, så att vi inte kan avgöra om resultatet beror på kontrasten XA och XB och/eller på inverkan av Z-variabler.
Experimentell kontroll är ett överlägset sätt att kontrollera ur logisk synvinkel. Det beror på att den oberoende variabeln kan manipuleras aktivt av försöksledaren och att försökssituationen i övrigt kan kontrolleras i princip med avseende på störande faktorer. Det kan ske genom att eliminera eller konstanthålla dem eller genom randomisering, dvs. slumpa ut störeffekterna på X-betingelserna så att de blir likvärdiga inom slumpens gränser.
Den allmänna principen är självklar. Genom att lägga restriktioner (kontroll) på försöket, så minskar osäkerheten i utfallet, och det blir enklare att dra slutsatser om orsak och verkan, dvs. att testa kausala hypoteser. Men fördelarna är begränsade till relativt enkla hypoteser och försök. Vi ska illustrera det genom att se vad som händer om det undersökta systemet inkluderar allt flera betingelser, dvs. blir mer komplext.
I det enklaste fallet har vi bara en betingelse A som vi vill undersöka effekten av. Det innebär en jämförelse med en kontrollbetingelse, som vi kan kalla icke-A, vilket innebär att vi inte förväntar oss någon effekt. Resultaten under respektive betingelse kallar vi YA och Y0.
Obeoende variabel: Betingelse A – Kontrollbetingelse icke-A
Beroende variabel: YA - Y0
”Den linjära modellen” är helt dominerande vad gäller dataanalys. Den beskriver det observerade resultatet YA som en linjär additiv funktion av ett väntevärde eller systematisk effekt a och ett slumpvärde e, dvs. YA = a+e.
Om man jämför A och icke-A under välkontrollerade former, så kan det förväntade resultatet beskrivas som en differens YA-Y0= (a+ e) - (a0+e) = a, där a0 betyder 0-effekt och slumpfelen e vanligtvis antas ta ut varandra i princip. I ett idealt fall är skillnaden mellan betingelserna alltså ett direkt uttryck för effekten a.
Om data är av kvalitativ art så uttrycker operationerna + och – olika logiska kombinationer; vid kvantitativa data har + och – sina vanliga aritmetiska betydelser.
Antag att försöket i stället gäller två samtidigt verkande variabler A och B, som vardera har två olika värden 1 och 2. Ett exempel är frågan hur lägesuppfattningen Y påverkas om lägesinformationen varierar i mängd A (a1=stor, a2=liten) och typ B (b1=bearbetad, b2=obearbetad).
Effekterna a och b på Y, där a=a1-a2 och b= b1-b2, kan beskrivas som:
Den linjära modellen av de kombinerade effekterna av A och B är
YAB = a + b + ab + e.
Formeln kan utläsas som att resultatet YAB kan tolkas som en summa av de enskilda huvudeffekterna a och b samt en särskild kombinationseffekt ab förutom en felterm e. Det som tillkommer är interaktionseffekten ab som uttrycker en effekt utöver summan av a- och b-effekterna. I själva verket visar en signifikant interaktionseffekt att den linjära additiva modellen egentligen inte är adekvat, eftersom ab beskriver en produkt eller multiplikativ effekt. När antalet variabler är litet, så kan man ändå skatta och tolka en interaktionseffekt någorlunda enkelt med hjälp av modellen.
I vårt exempel skulle lägesuppfattningen hypotetiskt kunna påverkas negativt av för liten informationsmängd (a-effekt) och av att informationen är bearbetad eller ej (b-effekt). En ab-effekt skulle kunna innebära att kombinationen av stor, bearbetad informationsmängd förbättrar lägesuppfattningen, medan en stor, obearbetad mängd försämrar den kraftigt. Figur 2.4.1 visar en sådan hypotetisk interaktionseffekt.
Figur 2.4.1. Exempel på interaktionseffekt av faktorerna informationsmängd
och bearbetning på lägesuppfattningen.
Men när antalet interagerande variabler ökar, så blir både den linjära modellen och den experimentella metodiken i praktiken otjänliga. Fyra interagerande variabler är i praktiken en övre gräns i ett experiment, som då kräver stora mängder observationer för att kunna tolkas överhuvudtaget. Vi kompletterar vårt tidigare försök med lägesuppfattning med ytterligare två faktorer, C = om lägesinformationen är distribuerad eller ej, samt D = om insatser ska göras samordnade eller ej. Detta ställer nu ytterligare krav på lägesuppfattningen, eftersom hänsyn eventuellt måste tas till samverkande förband och deras uppfattning om läget. Motsvarande linjära modell har följande utseende, om de fyra variablerna är A, B, C och D:
YABCD = a+b+c+d+ab+ac+ad+bc+bd+cd+abc+abd+acd+bcd+abcd+e.
Lägesuppfattningen Y kan i princip påverkas av var och en av de fyra faktorerna (huvudeffekter) men också av 11 olika interaktionseffekter. I princip kan dessa olika effekter kombineras på ett utomordentligt stort antal sätt. Tolkningsproblematiken är alltså formidabel. I praktiken blir oftast många interaktionseffekter omöjliga att testa, beroende på att man har för få försöksobservationer och för okänsliga metoder
Den generella linjära modellen ger en intuitiv förståelse av de praktiska och logiska svårigheterna att systematiskt kontrollera ett multifaktorexperiment och tolka de olika typerna av effekter. Men fyra samverkande variabler som i exemplet är ändå ett extremt enkelt fall, jämfört med vad som kan förekomma i komplexa system i den naturliga kontexten!
2.5. Alternativa ansatser att undersöka komplexa system
Ett komplext system kan i princip undersökas genom att man gör en serie välkontrollerade och lagom komplicerade experiment. Förutsättningen är dock att experimentplaneringen styrs av en kraftfull teori. Denna förutsättning finns inom naturvetenskap och teknik, men gäller inte för sociala system, särskilt inte när mänskligt tänkande och agerande spelar en väsentlig roll.
Genom att göra visst avkall på kontrollkraven kan man närma sig mer komplexa och naturliga situationer. I experimentella simuleringar kan man introducera vissa representativa drag från den naturliga kontexten, samtidigt som man fortfarande har aktiv experimentell kontroll över de viktigaste faktorerna. Vid fältstudier används kvasiexperimentella designer med varierande grader av kontroll över situationen. Värdet av resultaten är i allmänhet beroende av hur teoretiskt välgrundade studierna är.
Användbara teorier om komplexa sociala system och skeenden saknas generellt, vilket försvårar möjligheterna att undersöka dem. Vad kan då göras på vetenskaplig grund? Vi vill hävda att det finns två principiellt skilda ansatser att undersöka och förändra komplexa system och skeenden i naturlig kontext. Båda ansatserna utnyttjar den naturliga variationen och osäkerheten i stället för att försöka reducera den.
I den ena ansatsen utgår man från att det komplexa ”naturliga” systemet ändå har en rimligt enkel struktur eller processhierarki, som är möjlig att observera och beskriva. Ansatsen förespråkar avancerade fallstudier av multifaktortyp i naturlig kontext. Teoretiska principer och modeller bör styra analysen av det undersökta systemet (se Yin, 2003).
Den andra ansatsen är aktionsforskning, som liknar experiment i så måtto att man försöker påverka systemet, och att påverkan bör vara teoristyrd. Aktionsforskning bygger på bl.a. två antaganden som formulerades av socialpsykologen Kurt Lewin: (1) Ingenting är så praktiskt som en bra teori, (2) Om du vill studera en organisation (system, grupp), så försök då att förändra den.
Aktionsforskningen är besläktad med design och därför också med vetenskapligt grundat utvecklingsarbete. Ett aktionsforskningsförlopp kan innebära att man stegvis förändrar ett system genom att med olika medel uppnå delmål på vägen mot ett slutmål. Aktionsforskningen följer alltså primärt en mål-medel-modell, där medlen är underordnade ändamålen. Orsak-verkan-samband används sekundärt i den mån de är tillgängliga. Aktionsforskning kan likställas med en teknologi, om det inte vore för att aktionerna också kan bidra till att förstå systemets egenskaper (jfr Lewins andra tes).
3. PROBLEMANALYS – FORMELLA ASPEKTER
Varför bör man göra en explicit problemstrukturering och analys även i praktiskt inriktade projekt? Projekt och utvecklingsarbete gäller ofta komplexa uppgifter och sammansatta mål. I utgångsläget bygger emellertid projekt ofta på en oklar blandning av etablerad kunskap, övertygelser, visioner och värderingar. Projektbegreppet i sig avslöjar inte detta, eftersom det är rationellt definierat, vanligtvis i form av ett antal faser: t.ex. målformulering, planering, genomförande och rapportering. Denna rationella form döljer att det rör sig om en komplicerad process. Exempelvis projekt som gäller organisationsförändring lyckas sällan uppfylla sina mål, enligt de vetenskapliga utvärderingar som har gjorts.
En inte oväsentlig del i förklaringen till projektmisslyckanden kan ligga i oklara eller felaktiga utgångspunkter. I och för sig ligger det i projektets natur, som handlar om att upptäcka eller uppfinna nya medel för att uppnå mål. Problemlösning och innovation är ju en följd av osäkerhet om möjligheter och lösningar. Det krävs kvalificerat tänkande, men risken att ”gå bort sig” i problemrymden är stor. Känslan av att projektet bygger på skarpsinniga resonemang kan vara stark – men också illusorisk, vilket en utomstående betraktare kan avslöja när projektet i värsta fall redan har gått för långt. Därför bör man använda sig av vetenskapligt arbetssätt som en kvalitetssäkring av projektarbete.
3.1 Vad innebär problemanalys i projekt?
Rationell måluppfyllelse i projekt förutsätter att man planerar och använder medel för att nå målen. Planeringen inbegriper en analys av både mål och tänkbara medel. Analysen kräver man söker information om mål och medel, samt bearbetar och prövar den. Den säkraste vägen att inhämta information är givetvis att göra kvalificerade empiriska prövningar eller test. Men i utgångsläget är vare sig målen, tänkbara medel eller prövningskriterierna särskilt tydliga. Det innebär kanske att en förstudie måste göras. Men under alla omständigheter behöver man systematisera vad som finns av tillgänglig kunskap, och vilken ny kunskap som är nödvändig för att gå vidare i projektet. Problemanalysen bör alltså inledas med en rationell form för detta.
Formulering av prövbara hypoteser och specifika frågeställningar föregås av problemanalys (se Forsknings/utredningsprocessen, Figur 2.1). Problemanalys är en sammanfattande term, som betecknar analys av såväl forskningsproblem som utvecklings- eller designuppgifter. Vetenskapligt arbetssätt kräver att analysen är innovativ, eftersom målet är att skapa nya ”kunskapsprodukter”. Denna fas i FoU-processen skiljer sig därför från övriga faser genom sin relativa brist på regler och normer. Det egentliga kravet är blott att man kan logiskt härleda prövbara hypoteser och frågor från det ursprungliga problemet eller uppgiften – och motivera sitt förfaringssätt övertygande! Originalitet i tänkandet gör analysen slagkraftigare.
Problemanalysen är naturligtvis innehållsligt inriktad på det problem- eller ämnesområde, som ligger under problemet eller uppgiften. Det finns vanligtvis en begreppsapparat, vissa principer och eventuellt också teorier, som är relevanta i sammanhanget. Men det finns också formella aspekter på val av beskrivnings-system, som kan underlätta struktureringen och analysen av problemet. Det här kapitlet syftar till att ge några exempel på formella hjälpmedel.
3.2 Problemstrukturering
Med problemstrukturering menar vi första steget i problemanalysen. Det är någon form av formellt verktyg för att avgränsa och tydliggöra uppgiften. De formella verktygen ska ha helst vara allmänt användbara, dvs. tillämpas på olika typer av problem och uppgifter.
Ett ofta användbart sätt att inleda en problemstrukturering är att försöka avgränsa eller definiera en grundmängd av de objekt eller händelser som projektet gäller. De senare kallas element i grundmängden. Inom grundmängden kan man identifiera olika delmängder av element. Elementen och delmängderna av element kan vidare stå i olika relationer till varandra. Ett exempel på detta är ett ledningssystem, där individerna bildar en delmängd och teknik och utrustning en annan, och det finns relationer eller kopplingar såväl mellan individer som mellan individer och teknik/utrustning. Grundmängden av element samt mängden relationer mellan dem bildar tillsammans ett s.k. relationssystem.
3.3 Klassifikation
I ett enkelt typfall är utgångspunkten en allmän hypotes eller frågeställning, som ska brytas ner i mer specifika hypoteser. Frågeställningen är formulerad som en relation mellan två allmänna begrepp, och problemet kräver ingen speciell teoretisk strukturering. Problemanalysen leder till en kedja eller ett nätverk av allt mer specifika hypoteser. Figur 2.3.2 illustrerar ett sådant fall. Inom grundforskningen eller på välundersökta problemområden kan man finna dokumenterade exempel på sådana koncentrerade nätverk av hypoteser och begreppssystem. I praktiska sammanhang är däremot begreppsbilden ofta både unik och diffus; den måste konstrueras och ibland skräddarsys speciellt för att lösa uppgiften.
Ett exempel på en allmänt hållen frågeställning är: ”Hur påverkas individernas stridsvärde av den sociala kontexten på förbandet?” Specifikation eller nedbrytning till underordnade begrepp innebär klassifikation (Harré, 2002, kap.3). Den är grunden för själva existensen av skilda begrepp. Ett klassifikatoriskt system (taxonomi) är oftast hierarkiskt, dvs. överordnade begrepp indelas i underordnade på olika nivåer. Figur 3.3 är ett exempel på en hierarkisk klassifikation av begreppet ’social kontext’ (Hartley, 1999).
Figur 3.3. Klassifikatoriskt system av ’social kontext’ (Hartley, 1999).
En klassificering innebär att man måste ange vissa nödvändiga och tillräckliga villkor för att ett element ska ingå i klassifikationen (klassen av klasser eller grundmängden av element). I komplexa praktiska fall är det inte alltid lätt att definiera sådana villkor. Vad innefattas exempelvis under det allmänna begreppet ’social kontext’? Hartley’s egna deskriptiva definitioner på högre klassifikationsnivåer är vaga, t.ex. ’social struktur’ beskrivs som: ”By social structure, I mean the ways the particular event we are looking at is organised.” Men vi kan få en vägledning genom att granska hans definitioner av underklasser på de mer specifika nivåerna. Ju fler klasser eller nivåer klassifikationen har, desto mer precisa och användbara begreppskriterier innehåller den i allmänhet.
En viktig distinktion är mellan en klass’ intension och dess extension. Klassens intension innefattar de egenskaper som varje element i klassen har gemensamt med alla andra, dvs. de nödvändiga och tillräckliga villkoren för att tillhöra klassen ifråga. Klassens extension omfattar de faktiska elementen i klassen. I allmänhet gäller att ju mer specifik klassens intension är, desto mindre är dess extension, dvs. desto färre element ingår i klassen.
Motsvarande distinktion finns på det empiriska planet. Den empiriska innebörden av ett begrepp eller klass kan vara nominell eller reell. Den nominella innebörden utgör de empiriska kriterier eller operationer som används för att tillordna en empirisk händelse eller objekt till en bestämd klass. I beteendevetenskapen betecknar man dem som ”operationella definitioner”. Den reella innebörden i empiriska händelser/objekt är de faktiska faktorer som ligger under de nominella egenskaperna (och som bara kan beskrivas teoretiskt).
Klassifikation som ett logiskt begrepp förutsätter att klassifikationen är uttömmande (dvs. alla relevanta element kan klassificeras) och att klasserna är ömsesidigt uteslutande (dvs. ett element tillhör en och endast en klass). Elementen i en klass ska alltså stå i en ekvivalensrelation till varandra, dvs. vara likvärdiga i något avseende. En strikt klassifikation enligt logiska regler är i själva verket en förutsättning för att tillämpa ytterligare logiska och statistiska metoder. (Vi återkommer till detta i samband med genomgången av dataanalys.) I praktiken har det visat sig svårt att skapa klassifikationer av sociala fenomen, som uppfyller de logiska kraven. I exemplet illustreras detta av indelningen i sociala normer, regler och relationer som inte är alldeles entydig.
3.4 Sammansatta klassifikationer
Kombinationer av klassifikationer spelar en viktig roll för att beskriva komplexa fenomen. Ett exempel på en enkel 2×2-kombination fanns i avsnitt 2.4:
I detta fall vill man pröva effekter av alla tänkbara kombinationer. Hypoteserna kan gälla huvudeffekter och/eller interaktionseffekten. I andra fall, som t.ex. i sociala sammanhang, förekommer inte alla kombinationer i praktiken, vilket begränsar möjligheterna att testa vissa hypoteser.
Kombinerar man underbegreppen i Hartley’s delbegrepp – sociala normer, regler och relationer samt social och fysisk miljö – får man ett komplex av betingelser, vars storlek beror på antalet klasser i varje underbegrepp. Det minsta antalet möjliga klasser per begrepp är två; följaktligen är antalet kombinationer av betingelser minst 2×2×2×2×2=25=32. Problemanalysen kan då bestå i att överväga vilka kombinationsmönster, som har teoretisk och praktisk relevans och bör väljas ut för undersökning. Ett flertal specifika hypoteser om sambandet mellan social kontext och t.ex. individens stridsvärde kan alltså formuleras.
3.5 Kvalitativa och kvantitativa begrepp
Klassifikationer ger en indelning i kvalitativt olika begrepp. Den indelningen är fundamental i vår föreställningsvärld och i vetenskapen. Den ligger också bakom hur man formar kvantitativa begrepp, bl.a. i så måtto att numeriska tal avbildar egenskaper i kvalitativt skilda klasser (t.ex. talet ”2” kan representera händelser bestående av två aktörer, som skiljer sig från händelser med tre aktörer osv.)
Kvantitativa begrepp innefattar en speciell uppsättning logiska-matematiska villkor som motsvarar egenskaperna i formella numeriska system. Det är många gånger både praktiskt och teoretiskt fruktbart att avbilda verkligheten med numeriska eller matematiska system. En fördel är givetvis att avbildningen blir mer precis, när man använder ett numeriskt beskrivningssystem av företeelser, som faktiskt varierar kvantitativt i mängd eller intensitet. Exempelvis är en beskrivning av vindstyrkan i m/s mer precis än en verbal beskrivning i termer av kuling, storm etc. En annan fördel med att utnyttja en matematisk begreppsapparat är att den öppnar vägen för att använda en mängd olika modelleringsverktyg och statistiska metoder.
I exemplet med sambandet mellan social kontext och individernas stridsvärde uppkommer frågan tidigt i problemanalysen om den beroende variabeln ska behandlas som en kvalitativ eller en kvantitativ faktor. Begreppet ’stridsvärde’ är svårt att definiera och observera entydigt. Det bör därför behandlas som en inskjuten variabel. Följaktligen måste man välja minst en kvalitativ och/eller en kvantitativ indikator (specifik beroende variabel). Flera möjligheter står i princip till buds, t.ex. subjektiva data från intervjuer eller samtal klassificerade som ”stridsduglig” eller ”icke stridsduglig”, eller kvantitativa bedömningar på en skattningsskala från ”lågt till högt stridsvärde”. Alternativt utnyttjas objektiva data om uppträdande i eller inför kombattantsituationer, t.ex. med klasserna ”aktiv” och ”passiv”, eller kvantitativa data i form av exempelvis antal gånger individen deltagit som kombattant. Olika indikatorer kan ge olika resultat. Därför måste begreppsanalysen vara övertygande, när det gäller att härleda och formulera de specifika hypotetiska sambanden.
3.6 Matematiska modeller
I avsnitt 2.4 introducerades den generella linjära modellen i funktionsform. Den kan användas för att modellera både kvalitativa och kvantitativa relationer. En modell i matematisk form ger möjlighet att precisera både logiska och numeriska egenskaper, vilket kan förtydliga och underlätta problemanalysen. Exempelvis granskade vi en tänkbar linjär funktion mellan en beroende variabel och fyra samverkande faktorer. Modellen synliggjorde behovet att förenkla funktionen för att den skulle bli tolkbar. Det kan ibland ske genom att göra teoretiskt motiverade begränsningar, t.ex. genom att föra in antaganden om att vissa interaktioner inte är möjliga eller genom att aktivt eliminera eller konstanthålla dem i undersökningsdesignen.
Matematiska och logiska modeller finns i en mängd olika former och kan beskrivas i både symbolspråk och grafiskt. Grafiska modellverktyg används ofta för att åskådliggöra kvalitativa relationer mellan begrepp.
3.7 Processmodeller
Figur 3.7 ger ett exempel på en processmodell av en kommunikationsepisod med två aktörer (Hargie, 1994, ref. i Hartley, 1999).
Figur 3.7. Processmodell av kommunikation
(efter Hargie, 1994, publicerad i Hartley, 1999).
Modellen representerar en klass av händelser, som innefattar kommunikation mellan två parter B och S (interpersonell kommunikation). Andra viktiga egenskaper är att båda parterna kan vara sändare och mottagare av kommunikation, att processen kan vara cyklisk och inbegriper feedback. En kommunikationscykel kan t.ex. omfatta en sändning från en part och mottagning och reaktion från den andra parten. Parterna modelleras som delsystem, med input-, output- och feedbackkanaler. De har samma inre struktur, dvs. samma uppsättning ”mentala begrepp” inklusive relationer mellan dem. Det är uppenbart att det rör sig om en processmodell, där man ska kunna följa och beskriva ett bestämt förlopp, steg för steg. Begreppen och deras relationer står för olika tillstånd och transformationer av information.
Detta beskrivningssystem lägger vissa restriktioner på vilka typer av hypoteser, som kan genereras och prövas i en studie. Å andra sidan tillåter processmodellen stor variation i användningen. Den lägger exempelvis inga restriktioner på vad kommunikationen gäller. Själva förloppet kan avse olika tidsrymder, platser och aktörer. Aktörens ”mentala modell”, som representeras av fyra inskjutna begrepp, är visserligen grov men åtminstone inte oförenlig med kognitionspsykologiska fundament. Den tillåter att man kan representera varierande mentala tillstånd hos aktörer, t.ex. beträffande uppmärksamhetsfokus, kognitiva mål, avsikter och tolkningar av information, handlingsplanering och reaktionsmönster.
Vi ska granska närmare vad modellen säger oss om verkligheten, och i vilken grad denna beskrivning går att pröva empiriskt. Den mest påtagliga modellrestriktionen gäller ordningsföljden mellan olika processteg. I s.k. flödesmodeller är denna tydligt markerad i en processcykel, t.ex.
3.7.1. Exempel på processcykel.
Vad är egentligen en sådan processcykel en modell av? En mottagare får information (input data), behandlar och reagerar på den genom att sända information (output data). Det är lätt att identifiera och registrera input- och outputinformationen i den verkliga kommunikationen. Genom att granska sambandet mellan dem kan vi dra slutsatsen att en transformationsprocess (t.ex. någon form av tolkning) måste ha förekommit mellan input och output, eventuellt också dra en slutsats om dess egenskap. Utan ytterligare kunskap (data?) kan vi dock inte specificera mer än att det förekommer en enda processkomponent och formulera en hypotes om dess karaktär. Typ I är en vanlig kommunikationsmodell – en avbildning av vad som händer i situationen.
En annan typ II representeras av de inskjutna processerna hos en part – en ”mental modell” (Figur 3.7.2). Här antar vi (teoretiskt) att det inte är möjligt att observera de olika subjektiva processtegen direkt, utan de ligger hypotetiskt inbäddade i det stora process-steget (process data).
Figur 3.7.2. Processmodell med tre hypotetiska transformationer.
Modellen specificerar i detta fall mer än vad som kan identifieras och registreras empiriskt i situationen. Det finns fler oidentifierbara än identifierbara faktorer i modellen, och den utvidgade modellen II kan inte prövas annat än i samma form som Typ 1.
För att pröva Typ II-modellen krävs det dels ytterligare teoretiska specifikationer av vad de tre inskjutna delprocesserna innebär och dels utökade möjligheter att – helst experimentellt – variera och pröva input-output-relationerna. En annan möjlighet är att försöka observera och mäta delprocesserna direkt, vilket då förvandlar dem till identifierbara storheter. Logiskt gäller naturligtvis samma restriktioner som för att entydigt lösa ett ekvationssystem i matematiken, dvs. att antalet okända faktorer inte får vara fler än de kända.
3.8 Analytiska och förklarande modeller
Harré (2002, kap 3) påpekar att man bör skilja mellan två typer av modeller:
(a) analytiska modeller som idealiseringar av sina empiriska källor eller användningar, och (b) förklarande modeller som representerar det okända. Typ I-modellen i exemplet ovan skulle då vara en analytisk, idealiserad modell av kommunikationen (den empiriska källan) med syftet att beskriva den. Typ II kan representera en teoretisk ansats med syftet att förklara vilka specifika hypotetiska mekanismer, som krävs för att behandla input och producera en output. Mekanismerna är i så fall ingen idealisering av den observerade kommunikationen (den empiriska källan).
3.9 Kontroll- eller feedbackmodeller
Processer beskrivs vanligtvis med någon form av flödesmodeller. I enklaste fall kan en process beskrivas med en linjär, additiv modell och förloppet antas fortskrida i en riktning (rekursiv modell). En sådan modell används ofta för att beskriva en utvecklingsprocess, där varje utvecklingssteg (delprocess) bidrar till att nå utvecklingsmålet. Sådana sekventiella processer kan också kopplas parallellt som t.ex. i Figur 3.9.1.
Figur 3.9.1. Exempel på modell med sekventiella och parallella processer.
Särskilt komplexa system utmärks emellertid av olika former av kontroll- och anpassningsmekanismer. Exempelvis återförd information (feedback) från resultatet av en tidigare process utnyttjas för att korrigera denna. Feedback-mekanismer innebär att processen inte enbart fortskrider i en riktning, och en mer komplicerad (icke-rekursiv) modell behövs. En kontrollerad aktivitet eller verksamhet kan modelleras med hjälp av följande enkla modellkomponenter (Figur 3.9.2):
Figur 3.9.2. Exempel på sluten och öppen kontrollmodell.
Kontrollenheten mottar feedback-information om utförandet eller aktiviteten och omvandlar den till styrinformation. Den vänstra modellen är sluten, och kan inte påverkas utifrån. I den högra öppna modellen är kontrollkomponenten kopplad till omgivningen och kan både påverka och påverkas av denna.
Ett exempel på en hierarki av kontrollkretsar är avbildad i Figur 3.9.3 på två olika sätt som dock är logiskt likvärdiga. Den övre kontrollnivån är kopplad till sin omgivning, medan den lägre enbart kan påverkas indirekt utifrån. Observera att den lägre kontrollnivån representerar en utförandekomponent sett i ett högre perspektiv.
Figur 3.9.3. Exempel på likvärdiga hierarkiska kontrollmodeller.
Figur 3.9.4 visar ett exempel på kontrollmodell med vissa specificerade kontrollfunktioner.
Figur 3.9.4. Exempel på modell av kontrollfunktioner.
3.10 Problemstrukturering med hjälp av öppen systemteori
Projekt- eller problemområden kan beskrivas som öppna system. Ett öppet system är en modell av en del av verkligheten, som kan avgränsas från sin omvärld, men som står i växelverkan med den. Systemet består av en uppsättning element (noder) eller enheter, som ska motsvara objekt eller händelser i verkligheten, och som är relaterade till varandra. Figur 3.10 visar att det finns två huvudtyper av relationer (streck, pilar): mellan omvärlden och element inom systemet samt inbördes mellan systemelementen.
Figur 3.10. Principskiss av öppet system.
Observera att en hypotes om ett förlopp kan formuleras i systemtermer. Omvärldens (omgivningens) påverkan på systemet kallas input (insats, inflöde, instorheter) till systemet. Systemets påverkan på omvärlden betecknas output (resultat, utfall, utflöde, utstorheter). Systemets uppgift är att transformera input till output. Detta är systemteorins sätt att beskriva verksamheten i t.ex. organisationer eller organismer.
Exempelvis lägesinformation (X=input) påverkar lägesuppfatt-ningen (Y=output) genom en bedömningsprocess, transformationen P. I metodterminologi kan input sägas vara oberoende variabel, transformationen P är inskjuten variabel (processvariabel) samt output är beroende variabel.
Det är lätt att se hur systembeskrivningen kan tillämpas på verksamheter och organisationer. Exempelvis ett ledningssystem är i vissa avseenden (t.ex. fysiskt, administrativt, socialt) avgränsat från sin omvärld (t.ex. andra organisationer, samhället i övrigt, miljön) men står i växelverkan med den (genom att inhämta och sända information, tjänster och material, styra delar av omvärlden, göra och motta personliga besök, lyda under lagar och direktiv m.m.). Inom systemet finns det olika typer av element, t.ex. människor, kommunikationsmedel, maskiner, utrustning och många andra fysiska arrangemang, som står i komplicerade relationer till varandra och utgör en struktur.
I grundläggande systemteori beskrivs samspelet med omvärlden i form av överföring av energi eller information till systemet (input) och en omvandling (transformation) av den inom systemet, vilket resulterar i en produkt eller utflöde av energi eller information (output). Komplicerade system har många olika typer av input, output och transformationer.
Det praktiska syftet bestämmer hur pass detaljerad systembeskrivningen ska göras. Noggrannheten och precisionen måste vara avhängig sammanhanget och syftet med beskrivningen. Det är inte nödvändigt att begränsa beskrivningen till konkreta objekt eller händelser. Också mer abstrakta företeelser som t.ex. bedömnings-processer och ledningsfunktioner kan beskrivas i systemtermer som element eller relationer.
I vissa fall kan det vara lämpligt att infoga fler systemegenskaper i sin systembeskrivning. Utgångspunkten är att ett system för att klara kraven från en komplicerad och föränderlig omvärld måste ha en viss kapacitet. I systemteorin (Katz & Kahn, 1978) kan man beskriva även följande egenskaper förutom input, output och transformationer dem emellan:
(a) att transformationerna ofta har en cyklisk karaktär. De upprepas med mer eller mindre jämna mellanrum. Exempelvis kan detta regleras internt av program, scheman och arbetsordningar eller bero på aktiviteter i omvärlden. Transformationer har också ofta en hierarkisk uppbyggnad. Exempelvis handläggning av ett ärende kan förutsätta vissa underordnade rutinaktiviteter, som registrering och distribution av meddelanden. På högre nivåer kan ärendet föranleda tidskrävande bedömningar, medan själva beslutet kan ta kort tid. I exemplet omfattar cykeln hela tiden från registrering av det inkomna ärendet till det att ett beslutsmeddelande sänds ut till underställda enheter.
(b) Negativ entropi, vilket innebär att systemet importerar mer energi eller information än det exporterar. Denna import av energi och information är investeringar, som bidrar till att bygga upp systemets struktur och kapacitet för framtida bruk och extrema situationer.
(c) Informations- eller kontrollmekanismer. Systemet mottar information från yttre och inre källor, som måste bearbetas med hjälp av särskilda mekanismer eller operationer. Systemet styrs med hjälp av sådana informations- eller kontroll-processer.
(d) Dynamisk jämvikt. System försöker upprätthålla ett stabilt inre tillstånd genom att kontrollera och neutralisera yttre och inre krafter, som hotar detta tillstånd. Ett absolut jämviktsläge är svårt att upprätthålla i perioder med starka förändringar i tekniska, ekonomiska, sociala och kulturella faktorer. Jämviktsläget måste därför anpassas tid efter annan (dynamiskt).
(e) Likfinalitet: System kan ofta nå samma slutmål på olika sätt eller med olika medel. Detta faktum understryker behovet av att system är flexibla och anpassningsbara.
(f) Ett differentierat och specialiserat rollsystem. System med svåra uppgifter i en komplicerad verklighet måste själva ha en komplicerad struktur för att klara sådana situationer. Organisationer och andra system utvecklas i själva verket genom att bygga upp en mer komplicerad inre struktur. I organisationen innebär det specialiserade arbetsroller och arbetsuppgifter och uppdelning av organisationen i delsystem, t.ex. avdelningar, insatsstyrkor, instruktörsgrupper m.m. En för långt gången differentiering eller specialisering är emellertid av ondo. En organisation ska inte ha mer komplicerad struktur än vad som krävs för att fullgöra uppgiften under en viss tidrymd. Detta bestäms framför allt av kraven från omvärlden.
3.11 Modellens koppling till empirin
Den empiriska prövningen beror i mycket hög grad på hur problemanalysen har genomförts. De formella verktyg som exemplifierats i kapitlet kan bidra till att göra problemanalysen logisk och motsägelsefri. Men det avgörande kriteriet på en bra problemanalys är givetvis inte formell stringens, utan i vilken grad problemet eller uppgiften i verkligheten kan utsättas för relevanta empiriska testningar.
Begreppsmodellen måste alltså för det första avbilda den empiriska problem- eller uppgiftsstrukturen på ett adekvat sätt. För det andra måste begreppsmodellen kunna generera ett antal prövbara påståenden eller specifika frågor, som kan ges reliabla och valida svar.
När det gäller komplexa och dynamiska sociala system så är detta förenat med betydande svårigheter. Ett vanligt fel är exempelvis att bara modellera och analysera sådana delproblem och uppgifter, där det redan existerar förebilder och lösningar och lämna resten av systemproblematiken åt sitt öde. Ett annat fel är att modellera system med hjälp en linjär additiv modell, när uppgiften kräver en icke-linjär dynamisk ansats. Vanligt är också att man analyserar vissa systemegenskaper som om de vore oberoende och bortser från att de bildar ett integrerat relationssystem i verkligheten.
Brister i problemanalys och modellering leder ofelbart till att undersöknings-metodiken vrids i fel riktning, vilket ger en bristfällig begreppsvaliditet i resultaten.
3.12 Problemanalys som kontrollfunktion i FoU-arbetet
Eftersom problemanalysen ska vara en kreativ process, kan den i ett tidigt skede ge intryck av att vara delvis kaotisk. Problemanalysen är ingen enkel linjär process. Dess definitiva logiska karaktär är egentligen som tydligast i slutrapporten. I praktiken är problemanalysen dock avslutad i och med att genomförandefasen – datainsamling eller designarbete – inleds.
Man kan lägga två kontrollperspektiv på problemanalysen: ett framåtriktat (feedforward) och ett återkopplande (feedback). Figur 3.12 illustrerar dem.
– Problemanalysen kan ses som en strukturerad problemlösning för att formulera ett antal specifika hypoteser eller medel för att nå ett mål eller lösning. Analysen ska fortskrida logiskt utifrån givna teoretiska och empiriska premisser.
– Problemanalysen inkluderar också resultatet av återkopplingar, grundade på analyser av tänkbara konsekvenser och restriktioner.
Figur 3.12. Problemanalys som en kontrollfunktion i FoU-arbetet.


















